3 min to read
spark

spark是一个快速而通用的集群计算平台。快速的主要原因是在内存进行计算
运行模式
1.本地模式 Windows本地运行需要配置:System.setProperty(“hadoop.home.dir”, “C:\Program Files\winutils\”)
2.standalone模式
3.集群模式
spark与集群资源管理器是松耦合的关系,只需要可以申请到excutor运行所需的进程即可。所以支持多种集群管理组件对spark进行管理。
sparkContext 连接集群资源管理(yarn\k8s\mesos),申请excutors资源,将相关代码发送到excutors;
3.1 yarn管理
使用yarn作为spark集群管理很简单,只需要在使用spark_submit提交任务时,配置HADOOP_CONF_DIR或者YARN_CONF_DIR参数,这时候spark会自动作为yarn的客户端,申请资源(具体来说就是excutors),然后将所需代码传到excutor上,由driver调度执行。
yarn-cluster与yarn-clien模式的区别:
3.2 mesos
3.3 k8s
组件:spark core
spark core实现了spark的基本功能:与存储交互、任务调度、内存管理、错误恢复等;
application运行机制
通常来讲是每一个spark应用程序是由driver program执行用户定义的main函数开始的,main函数中首先要做的是创建sparkContext,主要作用是告诉spark应用程序运行的集群环境以及一些其他配置等。一个JVM中只能有一个active状态的sparkContext,用完之后记得stop。
RDD
弹性分布式数据集(resilient distributed dataset),具有只读-可并行计算-容错性等特点;可以由hdfs文件(包含hbase等各类以hdfs为基础的数据源)或者scala集合来创建RDD。RDD支持转换(transformations)和动作(actions)两类算子,前者主要是基于已有的RDD创建新的RDD,后者是将在rdd上计算的将结果传给driver program。Job就是根据action算子划分的
transformations类操作具有惰性(lazy),仅当action操作需要结果时才执行,这个特性也是spark更加高效的原因之一。默认情况下,每一次action都会触发与之相关的transformations,如果一个rdd会多次使用,建议进行持久化或者缓存。
Shuffle操作:指的是会引起数据的重分布的操作(re-distributing data);比如:repartition、coalesce、ByKey的操作以及join类别的操作,如:cogroup、join等。stage就是根据shuffle算子划分的
shuffle操作需要大量的IO、网络IO以及序列化等操作,比较耗资源。
以reduceByKey为例说明:
reduceByKey所有key相同的元素对应的值通过reduce函数进行计算,得到一个新的值。其中一个问题在于同一个key可能分布在不同的partition中,这样各个partition之间需要all to all的一些操作。需要读取所有partition的所有key-value,各个partition之间需要有数据交换,才能计算每一个key对应的最终的value。
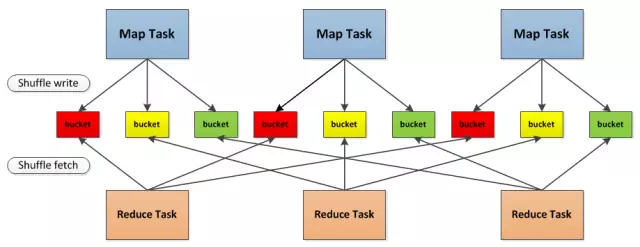
- hash based shuffle(现在已经弃用):3个 map task, 3个 reducer, 会产生 9个小文件,
Shuffle前在磁盘上会产生海量的小文件,此时会产生大量耗时低效的 IO 操作 (因為产生过多的小文件);
内存不够用,由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
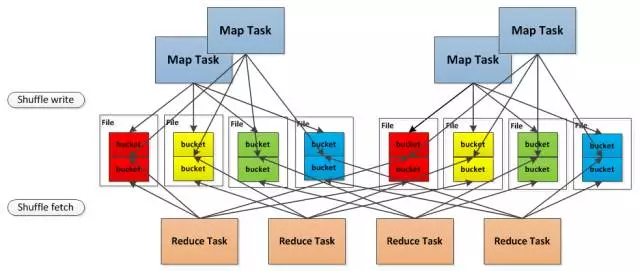
- Consolidated HashShuffle:4个map task, 4个reducer, 如果不使用 Consolidation机制, 会产生 16个小文件。但是但是现在这 4个 map task 分两批运行在 2个core上, 这样只会产生 8个小文件
数据交换之后,每个partition的数据就是确定的,partition之间是有序的,但是每个partition里面的元素是无序的。如果期待partition元素内部也是有序的,那么可以通过以下算子得到:
mapPartitions to sort each partition using, for example, .sorted
repartitionAndSortWithinPartitions to efficiently sort partitions while simultaneously repartitioning
sortBy to make a globally ordered RDD
shuffle调优方式
- 合理的设置partition数目
- 防止数据倾斜
- 合理配置一些参数,如excutor的内存,网络传输中数据的压缩方式,传输失败的重试次数等。
transformation类型操作
| 操作 | 含义 | 操作 | 含义 | |
|---|---|---|---|---|
| map | - | groupByKey | - | |
| filter | - | reduceByKey | - | |
| flatMap | - | aggregateByKey | 按照key聚合,返回的value类型U和聚合之前的value类型V可以不同,需要提供V merge到U的方法以及U与U merge的方法;可以认为reduceBykey是其特例 | |
| mapPartitions | - | sortByKey | - | |
| mapPartitionsWithIndex | - | join | - | |
| sample | - | cogroup | - | |
| union | - | cartesian | - | |
| intersection | - | pipe | - | |
| distinct | - | coalesce | - | |
| repartition | - | repartitionAndSortWithinPartitions | - |
Action操作
| 操作 | 含义 | 操作 | 含义 | |
|---|---|---|---|---|
| reduce | - | foreach | - | |
| collect | - | countByKey | - | |
| count | - | takeOrdered | - | |
| first | - | takeSample | - | |
| take | - | saveAsSequenceFile | - | |
| saveAsTextFile | - | saveAsObjectFile | - |
RDD 持久化
当一个RDD会重复使用时,可以选择持久化来缩短任务执行时间。(但如果数据量不是太大,重新生成RDD的时间消耗小于从磁盘或内存加载的时间时,就不宜持久化)
spark自动管理持久化之后的数据,会结合least-recently-used (LRU)算法删除数据。
持久化有如下几种方式:
| 持久化方式 | 含义 |
|---|---|
| MEMORY_ONLY | 将JVM中的Object缓存到内存中 |
| MEMORY_ONLY_SER | 将partition序列化为数组,然后缓存到内存中 |
| DISK_ONLY | 将JVM中的Objec将JVM中的Object缓存t缓存到磁盘 |
| MEMORY_AND_DISK | 将JVM中的Object缓存到内存中,内存放不下的缓存到磁盘 |
| MEMORY_AND_DISK_SER | - |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 |
将JVM中的Object缓存到内存中,但是会缓存两份到不同的node上,防止谋一份数据失效。 |
| OFF_HEAP | 与MEMORY_ONLY_SER类似,但是数据会缓存到堆外内存 |
Broadcast Variables
针对只读变量的数据共享机制。以比较高效的方式将只读变量共享到所有机器上,当然使用普通变量也能达到类似的效果,但Broadcast类型的变量更加高效,主要具有以下优点。
- broadcast类型变量可以保证只在executor的内存中存在一份,只需要发送一次。普通变量每个task都会发生一次数据传输。
- 将要传输的变量不需要实现Serializable接口
- 可以高效地传输较大的数据集
Accumulators
可以理解为一个只能进行加法操作的变量,spark有一些内置类型,如:longAccumulator、doubleAccumulator,用户也可自定义。Task在执行过程中只能调用其add方法,但是不能获取到他的值。只有Driver Progeam可以获取到它的值。常用的场景有计数、求和等。 示例:
val accum = sc.longAccumulator(“My Accumulator”)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
accum.value
Dataset
分布式数据集,可以由JVM对象或者外部文件构建;
DataSet元素的序列化不使用java 序列化或者Kryo序列化的方式,而是使用一个可序列化的Encoder完成。
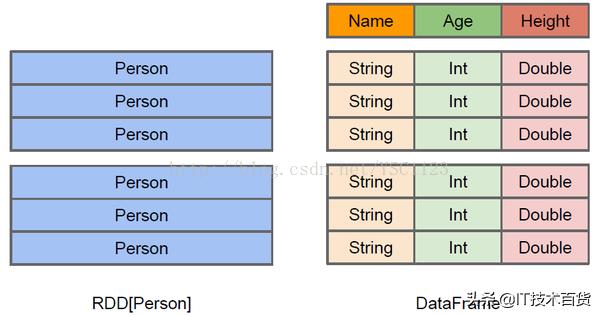
dataSet 与 RDD的区别
-
对于spark来说,并不知道RDD元素的内部结构,仅仅知道元素本身的类型,只有用户才了解元素的内部结构,才可以进行处理、分析;但是spark知道DataSet元素的内部结构,包括字段名、数据类型等。这为spark对数据操作进行优化奠定了基础。
-
DataSet序列化效率比RDD高很多,原因有二:其一是了解数据内部结构,不需要每一个元素都序列话字段名与数据类型,仅仅通过scheme就可以提供此信息;其二是引入了堆外内存,这在内存管理上可以更灵活自由,可以有效避免引起频繁的GC。
-
由于spark了解数据内部结构,并且引入了endcoder机制,所以在内存中以二进制的形式存储,区别于RDD以jvm对象的形式存储,所以在shuffle过程中不需要序列化与反序列化,另外也有提到在排序过程中不需要反序列化,个人觉得是整体元素不需要反序列化,但是对于排序所依据的字段可能仍然需要反序列化,但序列化的消耗肯定比整体反序列化要小很多。
-
dataSet可与SparkSql结合使用。RDD具有只读性,一般都是基于已有RDD创建新的RDD,SparkSql引擎结合DataSet,可以在一定程度上牺牲内部不变性(但对用户来说是无感知的),来减少对象的创建,避免频繁GC。另外Sql引擎本身也有很多的优化点。
-
dataSet支持更多的数据存取格式,如:csv、json、parquet、jdbc等。
总之,对于结构化数据,dataset比rdd在cpu、内存、任务耗时上都有很大的性能提升。但对于非结构化数据,往往还是使用RDD处理。
DataFrame
创建方式:基于RDD,Hive Table,Parquet Files,JSON Files等
窗函数
组件:spark mlib/ml
组件:spark stream
组件:spark graphX
一些优化策略
1.数据倾斜
表现:个别task执行任务时长远高于其他的task
解决方案:repartition
2.大数据join小数据
如果小数据可以被广播,则尽量不用join;
如果不能广播,可以按照key进行相同的repartition操作;
一些问题
万金油的方法:很多疑难问题可能是数据量太大导致的,所以先降低数据量,验证程序逻辑是否有问题,如果有就解决,没有那就可以判定是数据量大导致的;
如果是数据量大导致的,那么就在各个维度上分区处理,比如按时间分区,按用户地域分区等;或者是分阶段处理,将数据落地到磁盘,再开启下一个job。
-
解析parquet问题:
异常:org.apache.hadoop.fs.ChecksumException: Checksum error
问题原因:文件夹内包含一些隐藏的crc文件,这个文件是用于校验使用;如果存在则进行校验
解决办法:删除隐藏的crc文件 -
local模式资源限制
线程数目:local[2]
内存使用:.config(“spark.driver.memory”, “1g”)
spark.storage.memory - Total size of serialized results of 61362 tasks (1024.0 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
问题原因:1. worker 送回driver的数据太大引起的,spark.driver.maxResultSize控制worker送回driver的数据大小。优化代码,减少worker到driver的数据
- 分区太多,driver需要维护太多分区的状态等信息导致driver内存溢出,增加spark.driver.maxResultSize的大小,或者减少分区数
- 分区太多,driver需要维护太多分区的状态等信息导致driver内存溢出,增加spark.driver.maxResultSize的大小,或者减少分区数
-
Job 0 cancelled because SparkContext was shut down,
一般情况是: java.lang.OutOfMemoryError: Java heap space导致的。
如果在driver的日志里,找不到OOM,应该是excutor的OOM导致的。去Log Type: stderr这个地方的日志找
解决办法就是增加driver或者excutor的内存 -
shuffle.FetchFailedException: Direct buffer memory
增加:spark.yarn.executor.memoryOverhead
或减小:spark.executor.cores -
问题:处理某数据,num-excutors设置为2,执行失败,异常原因内存不足;设置为10 则可以执行成功。
原因推测:单个excutor处理的partition越多,带来的垃圾回收成本比较高,或者是处理的partition越多,即便处理完一个partition后,进行GC,内存也会逐渐增加,恢复不到处理之前的水平。 -
问题:引用类的static变量,在driver程序中修改之后的值,在excutor中不会生效
解决方式:使用广播变量 -
问题表象:driver与excutor通信异常,显示java.io.IOException: java.io.EOFException; Host Details : local host is…
Invocation returned exception on …
Futures timed out after [120 seconds]. This timeout is controlled by spark.rpc.askTimeout
最初推测是某个分区的文件异常导致的,但实际上更重要的是spark.rpc.askTimeout 这个参数,driver与excutor断开连接。
原因:driver内存不足,频繁FULL GC,导致driver与excutor失去连接
解决方式:优化代码(减少driver中创建对象的大小或者减小partition的数量) 或者 增加driver内存 -
问题:org.apache.spark.SparkException: Error communicating with MapOutputTracker(spark2.1)
原因推测:小数据量没有问题,大数据量会出现这个问题,推测可能是集群资源和计算力不足导致的,各种参考,调节了如下参数得以解决,具体是哪个参数发挥作用,暂时不清楚; 解决方式:
–num-executors 500
–conf spark.dynamicAllocation.maxExecutors=500
–conf spark.dynamicAllocation.enabled=false
–conf spark.shuffle.consolidateFiles=true - spark 读取json数据,某些行有错误;配置忽略.config(“spark.sql.files.ignoreCorruptFiles”, “true”)

Comments