1 min to read
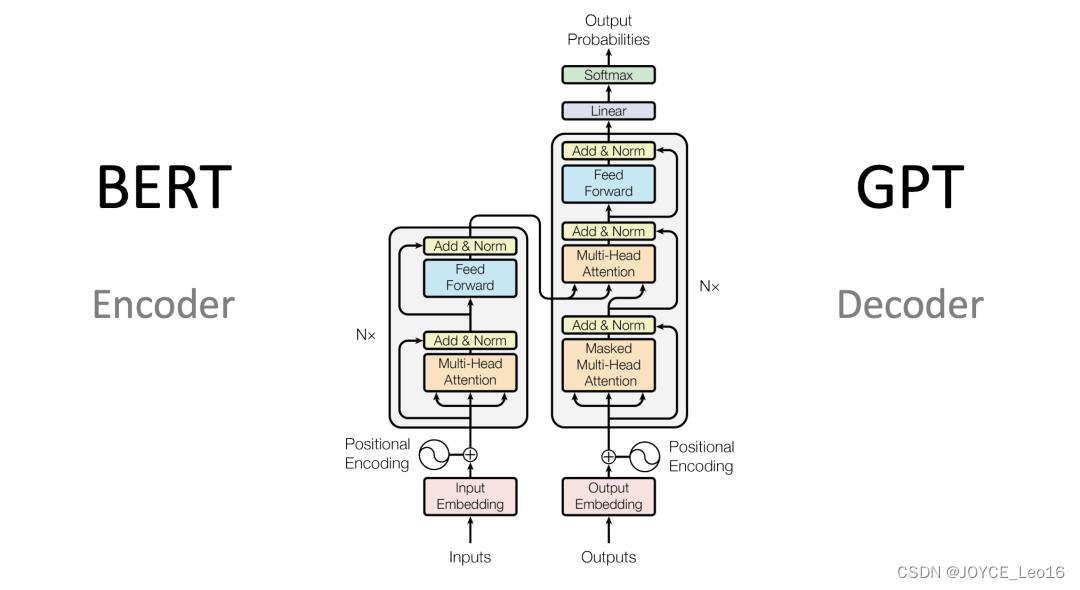
Transformer
简介
本质上依然是Encoder-Decoder架构,只不过在当中引入了:位置编码、self-attention、多头注意力、paddingMask和lookaheadMask以及经典的残差连接和归一化等,概念比较多,所以无论是理论还是实现都略微复杂,但并不是很难;
位置编码及应用
位置编码就是每一个位置信息的表示,计算方式如下:
PE(pos,2i) = sin(pos/pow(10000,2i/d))
PE(pos,2i+1) = cos(pos/pow(10000,2i/d))
这里的pos指的是字符(或词语)在seq中的位置,这里的i是维度等于d_model的一个向量,d是d_model的维度;
也就是在位置向量的偶数位置是通过正弦求得的,奇数位置是通过余弦求得。
特别说明的是,在第0和第1个位置,2i均为0;第2个和第3个位置,2i均为2;依次类推…
代码
下面以seq = 3;d_model = 5,为例,介绍位置编码的求解;
首先计算角度:
pos=np.arange(3)[:, np.newaxis] #array([[0],[1],[2]])
i=np.arange(5)[np.newaxis, :] #array([[0, 1, 2, 3, 4]]) 这里是维度为d_model的向量,也是pos_embedding的原型
#计算角度 angle的shape为3*5,其中3是由于pos导致的,5是由于i的维度导致的
angle=pos/np.power(10000,2*(i//2)/5) # 2*(i//2)的结果是[[0,0,2,2,4]] 很有规律
#拆分奇偶位置,并计算正余弦
sin=np.sin(angle[:,0::2])
cos=np.cos(angle[:,1::2])
#可能是考虑到embedding内部的位置对算法效果没有影响,因此再合并sin和cos的时候,并没有间隔插入合并,而是直接合并的
pos_encoding = np.concatenate([sin, cos], axis=-1)
pos_encoding = pos_encoding[np.newaxis, ...]
"""
不过后面再看tf官网示例时,写法如下:
# 将 sin 应用于数组中的偶数索引(indices);2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 将 cos 应用于数组中的奇数索引;2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
"""
这里最终每一个位置的向量维度与词语embeding的向量维度相同,两者按元素相加即可得出这个词在这个位置的向量表示;
注意力模型
这里理解起来会有一定难度,网上的各种介绍几乎也都是千篇一律的“官话”;闲话少叙,来看看以下介绍是不是可以让你更明白:
首先我们要理解注意力模型是在解决什么类型的问题,主要是解决在已经有一定的信息知识的条件下,判断某种情况对应的输出结果;
这里涉及三个变量:Q、K、V
K - 表示已经有的信息知识;
Q - 也就是上面提到的某种情况;
Q和K通过计算会得到一组权重,表示在Q这种情况下,K中各种信息的影响力;用这个权重与V进行元素对应相乘(可能会涉及到广播)就是模型的输出;
这里要求K的序列长度和V的序列长度相同,从物理意义上来讲对应位置的元素应该是有非常强的联系的;一般在模型中,K和V是相同的;
下面举一个例子: “我、是、程、序、员”这五个字可以表示为5×128维的向量,这个向量作为K和V;假设将“我” 作为查询向量Q(维度是1×128),首先计算权重,跟每一个词做点积会得到一个数值,最终得到1×5的一个向量,然后进行softmax 得到这5个词语对于“我”这种情况的一个权重(1×5),然后与V进行相乘,得到一个1×128维向量,这个向量可以表示“我” 在 “我是程序员” 这个句子的某些含义,比如:词性是“主语”
transformer中的self attention
Attention(Q,K,V)=softmax((Q*KT)/sqrt(d))*V
这里除以sqrt(d)的目的是为了梯度稳定,随着dmodel的增大,Q*KT的值也会增大;可以通过求导证明,对于softmax函数来说,变量x越大,导数值越小。
对于encoder来说,Q、K、V就是postion embedding和word embedding的求和得到的向量(暂且记为input),通过一层全连接得到;Q=Wq*input K=Wk*input V=Wv*input
对于decoder来说,??
multi-head attention
这个概念并不太好理解,但通过代码可以很明确的看出,就是将self attention 计算多次(权重并不共享);
至于这么做的目的并不是太清楚,优点类似于CNN中的filters参数。一般有以下两种解释:
- 扩展了模型关注不同位置的能力
- 为注意层提供了多个“表示子空间“
dropout
将输入向量(tensor)中的元素按照一定比例设置为0,其余元素按照一定比例扩大;
举例:
tf.enable_eager_execution()
input=tf.constant([1,2,3,4,5,6,7,8,9,10])
dropout=tf.keras.layers.Dropout(0.2) # 大约有20%的元素被设置为0,其余元素除以(1-0.2)
output = dropout(input,training=True) # 最终设置为0的元素个数可能占比20%,也可能占比0%,或者30%等等,并不是绝对的20%,没有被设置为0的,统一除以0.8
残差连接
目的
残差连接是为了解决神经网络退化问题,理论上来讲更深的网络性能一定比浅的好,但实践验证,网络层数越深,训练难度越大,有时候随着深度的增加,在训练集上的效果反而有所降低。
形式
残差神经网络的形式大致是这样的:在某一层较深的网络中,正常情况下是将上一层的输出F(x)作为这一层的输入,为了降低学习难度,将最初或者是前面某一层的输出叠加到这次的输入上,也就是将F(x) + x作为输入。
基本上和CNN中的shot-cut概念类似;
原理
归一化
目的
计算形式
参考
原理
mask
mask只会应用在self-attention的计算中,通过mask将相应位置的权重设置为极小值,表明不会关注到此位置的信息;
具体来讲就是计算完scaled_attention_logits = matmul_qk / tf.math.sqrt(dk) 这一步之后,在softmax之前,将padding位置的值变为极小值
# scaled_attention_logits 的shape是(batch_size,seq_len,seq_len)
if mask is not None: #mask的shape是(...,seq_len,seq_len)或者可以广播为这个shape,因为最终要和scaled_attention_logits 相加;
scaled_attention_logits += (mask * -1e9)
# 这样再对scaled_attention_logits进行softmax时,相应位置的权重就变得非常小
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
paddingMask
paddingMask 会应用在编码层和解码层所有的self-attention中,目的是使得padding位置不受到关注;
举例:
seq_len=5,其中padding位置为1个,那么最终的padding mask的shape为1*5,可以广播为5*5,最后一列元素为1表示mask,其余元素为0;scaled_attention_logits的shape为(batch_size,5,5),针对5*5的矩阵,第一行表示第一个单词对于这5个单词的关注度,第二行表示第二个单词对于这5个单词的关注度,依次类推…
但实际上无论是第几行,都不需要关注最后一个元素,因此将各行最后一个元素设置为极小值,再进行softmax,最终得到的关注度就是0;
lookAheadMask
lookAheadMask只会应用在解码层中的第一个multi-head-attention(实际上这里的mask时lookAheadMask和paddingMask的结合);目的是使得解码过程中,某一个位置的字符不能够看到后面的字符;
举例:
训练及预测过程中,由于第一个mha的K,V是解码结果的信息,因此需要保证每一个位置不能利用后面的信息,也就是第一个单词只能关注第一个单词,第二个单词只能关注第一个和第二个单词,依次类推,也就是说这里每一个查询单词的上下文是不一样的(编码器层可以认为每一个查询单词的上下文是一样的),seq_len=5,构造对角线及其下三角都为0的5*5矩阵,这样与scaled_attention_logits的5*5矩阵相加之后,第一行只有第一个元素权重为1,其余权重为0,第二行只有前两个元素有权重,其余元素都没有权重,依次类推; 这样就保证了每一个单词只利用自己以及前面单词的信息来生成对应的输出。
编码器层
- 输入:pos_embedding + word_vec 构成的seq;比如shape=(16,100,512) 其中16是batch_size, 100是seq长度,512是embedding维度
- 首先经过multi head attention,最终输出shape是:(16,100,512)
- mha层输出之后经过了一层dropout层,防止过拟合;
- 残差连接+LayerNormalization,解决深度神经网络退化与梯度消失问题(通过归一化,尽量防止数据落在激活函数的饱和区);
- 之后再经过两层全连接,首先是激活函数为relu的全连接,再之后是一层没有激活函数的全连接,最终的输出shape依然是(16,100,512)
- 最后再使用残差连接+LayerNormalization;
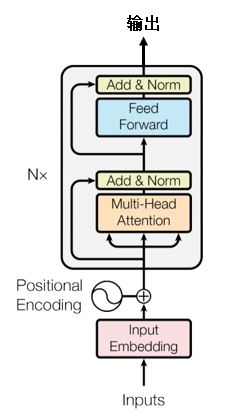
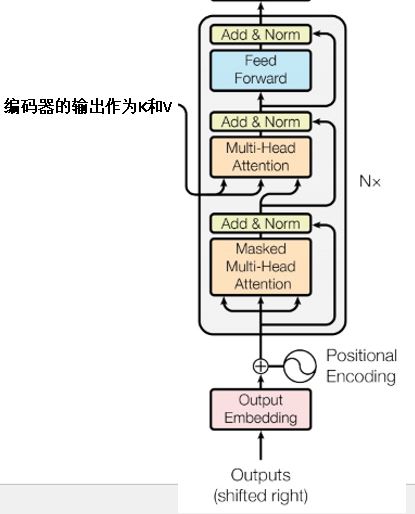
解码器层
解码器层包含两个mha,这两个mha与编码器的很相似,但各有一些特点;
第一层mha的主要特点是mask,也就是使用到了上面提到的lookAheadMask
第二层mha的主要特点是K和V来自于编码器的输出,Q来自于第一层的输出
再之后类似于编码器层,是两层全连接神经网络。

Comments