1 min to read
Python解析svg文件
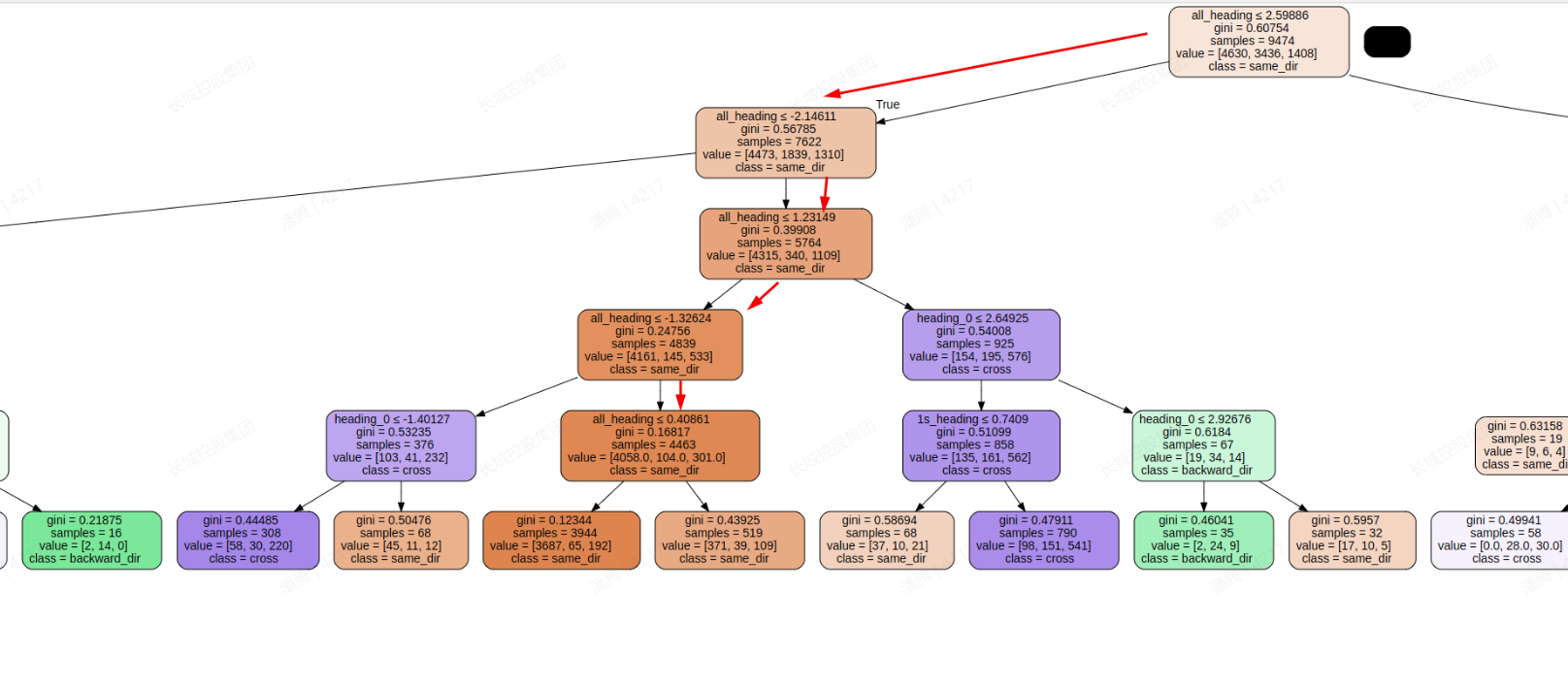
应用场景:使用sklearn机器学习库,训练决策树模型,导出svg格式的图片;
然后用这个代码解析成txt格式,便于工程加载;
import xml.etree.ElementTree as etree
tree = etree.ElementTree(file=r'example.svg') # 保证每次操作均为原始model文件
root = tree.getroot()
nodes = {}
edges = {}
for child in root:
if 'class' not in child.attrib or child.attrib['class'] != 'graph':
continue
for node_or_edge in child:
if 'class' not in node_or_edge.attrib:
continue
if node_or_edge.attrib['class'] == 'node':
node = {}
for node_kv in node_or_edge:
tag = node_kv.tag.replace('{http://www.w3.org/2000/svg}', '')
txt = node_kv.text
if tag == 'title' and txt.isdigit():
node['node_id'] = int(txt)
if tag == 'text':
if ' ≤ ' in txt:
node['feature'], node['threshold'] = txt.split(' ≤ ')
node['threshold'] = float(node['threshold'])
if 'class = ' in txt:
node['class'] = txt.replace('class = ', '')
# 不同类别的样本数量
if 'value = ' in txt:
s = txt.replace('value = [', '')
s = s.replace(']', '')
lable_counts = s.split(', ')
unknown_count = int(float(lable_counts[0]))
left_turn_count = int(float(lable_counts[1]))
right_turn_count = int(float(lable_counts[2]))
sample_count = unknown_count + left_turn_count + right_turn_count
node['sample_count'] = sample_count
node['unknown_prob'] = unknown_count / sample_count
node['left_turn_prob'] = left_turn_count / sample_count
node['right_turn_prob'] = right_turn_count / sample_count
if 'node_id' in node:
nodes[node['node_id']] = node
if node_or_edge.attrib['class'] == 'edge':
for node_kv in node_or_edge:
tag = node_kv.tag.replace('{http://www.w3.org/2000/svg}', '')
txt = node_kv.text
if tag == 'title':
from_id, to_id = txt.split('->')
from_id = int(from_id)
to_id = int(to_id)
if from_id in edges:
edges[from_id].append(to_id)
else:
edges[from_id] = [to_id]
# 设置左右子树
for from_id in edges:
left_id, right_id = edges[from_id]
nodes[from_id]['left_node_id'] = left_id
nodes[from_id]['right_node_id'] = right_id
nodes_vec = []
for i in range(max(nodes) + 1):
nodes_vec.append(nodes[i])
nodes_json = {'nodes':nodes_vec}
import json
with open('data.json', 'w') as f:
json.dump(nodes_json, f, indent = 3)
Comments