2 min to read
Java集合类

两个终极接口Collection和Map;
Collection下面主要是List、Set、Queue
List
继承关系如下:
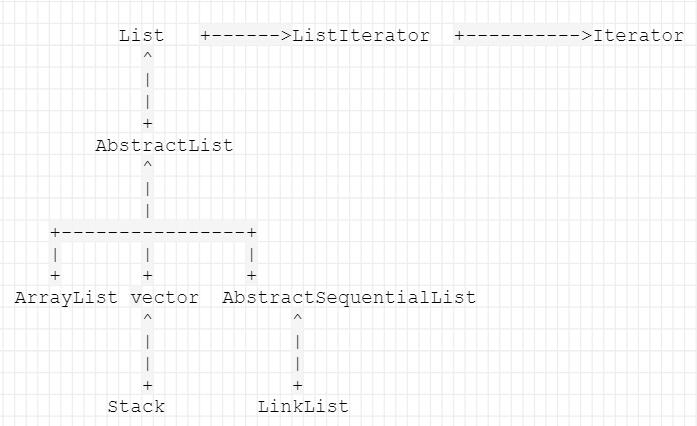
ListIterator相比iterator增加了:add、set、nextIndex、previousIndex以及前向访问相关方法。
ArrayList: 使用数组存储transient Object[] elementData;,当List为空时,默认共享同一个静态变量。当第一个元素加入到List时,数组默认大小是10,当插入元素时如果发现空间不够,首先扩展为原来的三倍,如果还是不够,则需要多少就创建多大的数组。最大是Interger.MAX_VALUE;由于扩容造成的内存浪费,可以使用trimToSize方法解决
ArrayList并非是线程安全的。
Vector: 使用数组存储,与ArrayList的主要区别在于 很多方法是同步实现的。
Stack: 基于Vevtor实现栈结构。很多方法也是线程安全的。提供了search方法,可以返回被搜索元素到栈顶的距离。
LinkedList: 元素以Node的方式存储,只记录头结点和尾结点,其余结点通过Node之间的指针关联。Node定义如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList实现了双向队列接口
Map
继承关系如下:
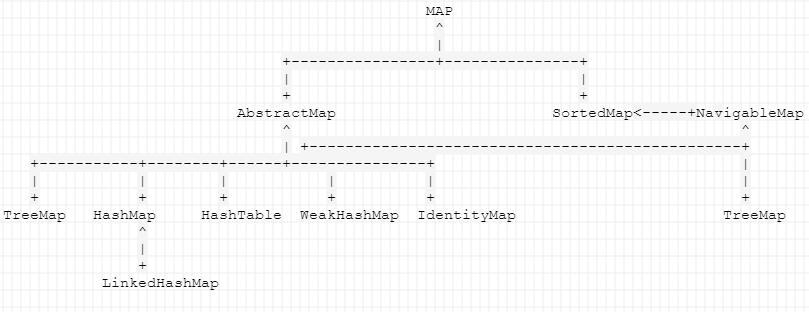
备注:图中缺少了CorrentHashMap
可以认为Map就是元素为Entry的集合,keySet和valueSet只不过是其另外的展示形式。
HashMap:采用数组+链表+红黑树实现。首先是以数组的形式存储Node,数组的扩容根据负载因子(数组的使用率),默认当使用率超过0.75就扩容为原来的2倍。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
transient Node<K,V>[] table;
当插入元素的时候,先根据key找到该元素在数组中应该对应的位置,如果该位置为null,则直接将新的Node放到该位置。否则判断该位置是TreeNode还是链表Node,如果是TreeNode,则加入到红黑树中,如果是链表Node,则放到链表最后。加入到链表最后时,检查是否超过“链表转树的阈值”,如果超过则转为红黑树。数组的该位置应该是红黑树的根。
if ((p = tab[i = (n - 1) & hash]) == null) //hash 是根据key得来的
tab[i] = newNode(hash, key, value, null);
...
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
...
LinkedHashMap:是HashMap的子类,与HashMap的主要区别是可保证有序迭代,迭代的顺序是key插入的顺序。主要是自己实现了Entity类,可以认为是一个双向链表的Node。数据存储上应该是跟HashMap一样的。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
TreeMap:使用红黑树存储数据。
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
...
WeakHashMap:使用数组加单向链表存储,没有使用红黑树。与其它Map的主要区别是Entity定义时继承了WeakReference类。
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
Entry<K,V> next;
/**
* Creates new entry.
*/
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
...
个人理解:对于其他Map,如果将K,V放入到其他Map中,只要这个Map不被回收,那么这个K,V便不会被回收,即使在其他任何地方都没有引用。但是如果放到WeakHashMap中,通过K构造的是弱引用的Entity,super(key, queue);,当K在外部没有引用时,这时候Map的Entity是可回收的。这种特性一般用于缓存场景。
关于弱引用:弱引用在垃圾回收时会被回收,无论外部是否还有引用。 弱引用可以和队列联合使用,当弱引用被垃圾回收后,通过弱引用的get方法会返回null值。在和一个队列关联的情况下,那么这个对象就会被放到引用队列中,后续可能需要自己去处理这个队列。WeakHashMap就是保存了这样一个队列,某些时刻就会从map中清除队列中的元素。
HashTable:不允许null作为key或者value。通过数组加链表实现。最大的特点就是很多方法都使用了同步。
ConcurrentHashMap: 利用分段锁更高效的实现了线程安全。具体细节:??
IdentityHashMap:最大的特点是在判断key和value是否相等的时候,使用的是‘==’而不是‘equal’;在一些涉及到拓扑关系的应用中较多。使用数组实现,第i个存储key第i+1个存储value。
Set
继承关系如下:
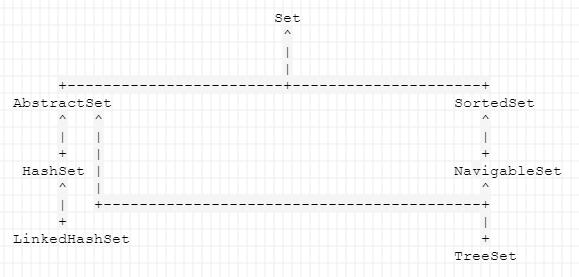
HashSet:使用hashMap存储数据,提供了构造方法,可将hashMap换成LinkedHashMap,但是外部不可以调用,貌似专门为LinkedHashSet设计的。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
TreeSet:默认使用treeMap存储数据,可定制传入实现NavigableMap接口的对象即可。
LinkedHashSet:HashSet的子类,使用LinkedHashMap存储。
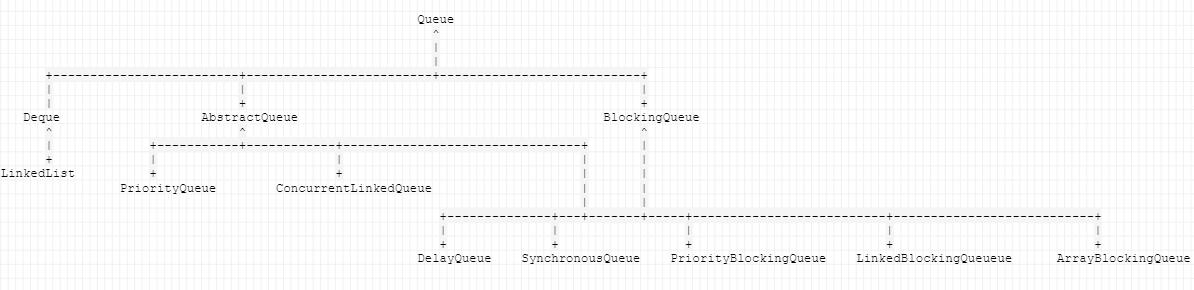
Queue
继承关系如下:
Queue接口如下:
| 方法名 | 操作 | 备注 |
|---|---|---|
| add | 增加一个元索 | 如果队列已满,则抛出一个IIIegaISlabEepeplian异常 |
| remove | 移除并返回队列头部的元素 | 如果队列为空,则抛出一个NoSuchElementException异常 |
| element | 返回队列头部的元素 | 如果队列为空,则抛出一个NoSuchElementException异常 |
| offer | 添加一个元素并返回true | 如果队列已满,则返回false |
| poll | 移除并返问队列头部的元素 | 如果队列为空,则返回null |
| peek | 返回队列头部的元素 | 如果队列为空,则返回null |
阻塞队列的方法
| 方法名 | 操作 | 备注 |
|---|---|---|
| put | 添加一个元素 | 如果队列满,则阻塞 |
| take | 移除并返回队列头部的元素 | 如果队列为空,则阻塞 |
Deque: 双端队列,可以先进先出,也可以后进先出。
PriorityQueue: 队列元素时有序的,无容量限制,基于有序堆实现(小顶堆,平衡二叉堆)。这里的堆采用的是数组结构存储。插入和删除的时间复杂度是O(log(n)).需要注意的是iterate是继承自collection的,所以使用iterate遍历并不能保证有序遍历。不允许有NULL元素。
ConcurrentLinkedQueue:无界,线程安全的Queue,先进先出。基于单向链表实现。
ArrayBlockingQueue:有容量限制,使用固定大小的数组存储队列元素。在内部记录了下一个要写入元素和取出元素的索引,所以实际上是一个环操作,并不存在移动元素。并且一旦创建队列;队列的容量就不可以再改变。并且提供了一种公平的机制可以对生产者和消费者进行排序。这种公平机制通过ReentrantLock来实现。
LinkedBlockingQueue:基于单向链表实现,无容量限制。
PriorityBlockingQueue:与PriorityQueue区别在于插入和读取元素时,如果队列是满的或者空的,可以阻塞。
DelayQueue:实现了BlockingQueue接口,无界队列,使用PriorityQueue存储数据;所放置的对象必须实现delay接口。队列是有序的。
SynChronousQueue:自身不会存储数据,每次插入数据都会阻塞,直到其他线程取数据。
从代码来分析,BlockingQueue 是线程安全的,在插入和读取元素时都加了锁。
面试
1.HashMap 和 HashTable的区别
存储层面,HashMap采用数组+链表+红黑树实现,而HashTable是数组+链表实现
HashTable不允许null作为key或者value,hashMap允许null作为key/value;理由是多线程条件下,get方法返回null时不确定是该key不存在,还是key对应的值是null;hashMap在单线程条件下,可以用containsKey判断是否存在,而hashTable多线程条件下,containsKey与get不能保证原子性,所以containsKey的结果不能用于get返回的判断。
Comments