1 min to read
Java内存结构与垃圾回收

====
大致分为四部分堆、栈、方法区、程序计数器
栈和程序计数器每个线程独有的,不共享;堆和方法区是各个线程共享的。
堆
堆中存放的是java对象实例,在JDK8中,String常量池也存在于堆中。
进一步细分为新生代和老生代;新生代内存是连续的,所以分配很快,新生代又分为3部分,分别命名为Eden,from,to;具体区别在总结垃圾回收时详细说明;
栈
存储基本类型的变量和对象在JVM的地址;可以细分为虚拟机栈和本地方法栈;栈是由栈桢构成,可以把一个方法当作一个栈桢;方法的执行就是栈桢进栈和出栈的过程。
方法区
用于存储类信息(类全限定名,访问权限,超类,字段的权限类型名称等),静态变量,方法(名称,权限、输入输出、字节码、异常表),类加载器的引用(加载类时用到的类加载器),类实例(并不是指new的实例,而是通过Class.forName()获取的类实例)
程序计数器
也是虚拟机的一小块内存,可以看作是字节码行号指示器,会记录正在执行的java字节码的行号,通过改变这个行号来选取下一条要执行的指令;常见的分支、跳转、循环、异常等都需要依赖行号指示器实现。
内存设置
设置项|含义 –|– -Xmx|堆的最大内存| -Xms|堆的初始值(最好与-Xmx保持一致)| -Xmn|年轻代大小 -XX:NewRatio|年轻代与老年代的比例(默认是1:2) -XX:SurvivorRatio|设置eden与from的比值,默认为8即年轻代按8:1:1划分 -Xss|线程栈的大小,默认为1M -XX:MaxPermSize|持久代大小
垃圾回收算法
复制算法
大体思路是将内存分成1:1两部分,其中一个称为from;另一个称为to;从from的根对象(根一般是在虚拟机栈、本地栈、方法区中存有引用的对象;)开始进行深度遍历,遇见存活的对象就复制到to中,对于已经复制过的对象会被标记为copied,并在forwarding中记录新对象的地址以便于其余引用的修改。当复制完成后,就会清除from中的数据;
另外还有一种改进的复制算法(cheney复制算法),大体思路相同,只不过是采用广度优先搜索;首先复制根对象(如A和B),这时有两个指针,scan指向A,free指向内存的下一个存储位置(B后面的空闲内存);之后对A进行搜索,搜索完毕时,scan指向B;free随着复制进行移动,一直指向下一个空闲位置;直到scan和free两个地址相等。详见: https://blog.csdn.net/u014228375/article/details/68957510 这样做的好处是相比递归迭代(深度搜索),可以抑制调用函数的额外负担和栈的消耗,缺点是相关联的对象在内存上未必是相邻的;
复制算法适用于存活率较低的情况下,这样遍历耗时比较小。所以通常用于新生代的垃圾回收。
缺点:浪费内存,总有一半的内存空间不能得到充分利用。(为了优化这个问题,新生代将内存分为了三部分,而不是两部分)
优点:回收之后,没有内存碎片化的现象,并且相关联的对象物理上距离比较近,与缓存兼容性更好,有利于提高访问性能。只遍历一遍,并且只遍历活的对象,耗时相对较少。
标记清除算法
该算法一般应用在老年代。
标记阶段:类似于复制算法,找到所有可访问的对象,做个标记(每个对象有一个mark字段,默认是false),mark置为true。
清除阶段:遍历堆中的所有对象,如果mark为false则直接回收,如果为true,则置为false。
优点:可以解决循环引用的问题。在内存不足时才执行,
缺点:在回收阶段,需要stop the word;效率比较低;会带来内存碎片化问题。
标记整理算法
标记阶段:与标记清除算法相同。
整理阶段:遍历所有对象,对于存活对象向内存的一端移动,遍历完毕之后直接回收端外的所有内存。
优缺点:主要解决了标记-清除算法的内存碎片化问题,但是整理移动元素的过程带来了一定的时间消耗。
垃圾回收器
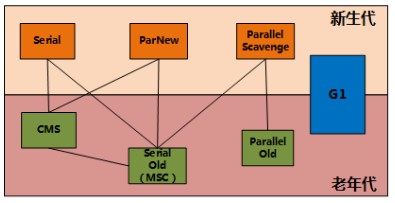
Serial & Serial Old收集器
ParNew
Parallel Scavenge & Parallel Old
通过-XX:+UseParallelGC -XX:+UseParallelOldGC设置新生代和老生代使用并行收集器,前者设置的是新生代收集器,后者设置的是老生代收集器。(Old设置之后,新生代默认是Parallel)
这里是并行收集器,并不是并发收集器。(并行:多线程进行GC,并发:GC线程与用户线程同时工作)
CMS
针对老年代的并发收集回收器,采用标记-清除算法,目的是为了获取最少停顿时间,一般应用在与用户交互多的场景。
-XX:+UseConcMarkSweepGC 参考文档:https://docs.oracle.com/javase/8/my_docs/technotes/guides/vm/gctuning/cms.html
- 初始标记,仅标记root对象,速度很快但会STW
- 并发标记,非STW
- 重新标记STW,修复并发标记过程中因用户程序运作导致的变动。
- 并发清除,非STW
一些配置:
| 配置项 | 含义 |
|---|---|
| -XX:CMSInitiatingOccupancyFraction默认值70 | 内存占用率大于70%时启动垃圾回收 |
| -XX:+UseCMSCompactAtFullCollection | JDK9中已经移除 |
| -XX:+CMSFullGCsBeforeCompaction | 表示进行多少次CMS GC之后,来一次压缩整理。 |
G1
-XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200
设计初衷是为了尽量缩短处理超大堆(大于4GB)时产生的停顿。
内存结构:在物理上不再划分新生代和老生代,因此也不需要设置新生代与老生代的大小。而是统一划分为一个个的region,一部分属于新生代(eden和survior),另一部分属于老生代(old)。还有一部分特殊的区域Humongous(多个region构成)用于存储大对象(大于region大小的50%)。
两种GC模式(Young GC和Mixed GC)
新生代的GC采用复制算法,并行回收,依旧会stop the world。
新生代分为了两部分,eden和survivor区域。当分配对象时,如果eden的空间不够,就触发新生代的GC。eden中的存活对象移动到survivor区域中,survivor中的某些对象可能移动到老年代或者新的survivor。如果survivor区满了,eden中的对象可能直接到Old区域。
- 阶段1:根扫描静态和本地对象被扫描
- 阶段2:更新RS处理dirty card队列更新RS
- 阶段3:处理RS检测从年轻代指向年老代的对象
- 阶段4:对象拷贝拷贝存活的对象到survivor/old区域
- 阶段5:处理引用队列软引用,弱引用,虚引用处理
Mix GC:XX:InitiatingHeapOccupancyPercent 默认值是45,老年代的占用空间与堆的比值达到或超过这个值时(45%),就触发老年代的回收。这时依旧会先进行young gc,然后再对部分老年代的region进行GC。mix gc的四个步骤如下:
- 初始标记STW:对根进行标记,将跟对象压入一个栈中。此过程借助yong gc的执行。
- 并发标记,非STW:这个阶段从GC Root开始对heap中的对象标记,标记线程与应用程序线程并行执行,并且收集各个Region的存活对象信息。
- 最终标记,STW:标记那些在并发标记阶段发生变化的对象,将被回收。
- 清理,STW:
如果配置合理,不会发生full gc,但如果内存消耗太快,mixed GC无法跟上内存分配速度时,会采用serial old GC垃圾回收器进行Full GC。
Remembered Set区域:辅助GC的一块存储区域,用空间换时间,逻辑上来讲每个region对应一个R set区域,记录这个region中的哪些对象被其他对象引用了。
humongous Objects:
Pause Prediction Model,停顿预测模型:
三色标记法:
SATB(Snapshot-At-The-Beginning):
常用配置
| 参数/默认值 | 含义 |
|---|---|
| -XX:MaxGCPauseMillis=200 | 设置期望达到的最大GC停顿时间指标(JVM会尽力实现,但不保证达到) |
| -XX:InitiatingHeapOccupancyPercent=45 | 启动并发GC周期时的堆内存占用百分比. G1之类的垃圾收集器用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比. 值为 0 则表示”一直执行GC循环”. 默认值为 45. |
| -XX:NewRatio=n | 新生代与老生代(new/old generation)的大小比例(Ratio). 默认值为 2. |
| -XX:SurvivorRatio=n | eden/survivor 空间大小的比例(Ratio). 默认值为 8. |
| -XX:MaxTenuringThreshold=n | 提升年老代的最大临界值(tenuring threshold). 默认值为 15. |
| -XX:ParallelGCThreads=n | 设置垃圾收集器在并行阶段使用的线程数,默认值随JVM运行的平台不同而不同. |
| -XX:ConcGCThreads=n | 并发垃圾收集器使用的线程数量. 默认值随JVM运行的平台不同而不同. |
| -XX:G1ReservePercent=n | 设置堆内存保留为假天花板的总量,以降低提升失败的可能性. 默认值是 10. |
| -XX:G1HeapRegionSize=n | 使用G1时Java堆会被分为大小统一的的区(region)。此参数可以指定每个heap区的大小. 默认值将根据 heap size 算出最优解. 最小值为 1Mb, 最大值为 32Mb. |
参考:
https://blog.csdn.net/qq_19917081/article/details/54585099
https://blog.csdn.net/j3T9Z7H/article/details/80074460
https://www.cnblogs.com/yunxitalk/p/8987318.html
https://tech.meituan.com/g1.html
https://www.jianshu.com/p/bc42531b28f3
GC相关设置
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。值太小的话容易导致频繁GC。
新生代GC过程
对于新生代来说,创建对象时首先在在Eden中分配(对于某些占内存比较大的对象,可以通过-XX:PretenureSizeThreshold 配置直接分配到老年代);如果Eden内存不够,则发起minor GC,将Eden中的对象转移到to区,同时会扫描from中的对象,决定是到to或者是到老生代。可以认为每经过一次GC,对象的年龄就增加1岁。大于指定年龄(-XX:MaxTenuringThreshold)或者是所有对象占用内存只和大于from/to的内存,就会进入老生代。
老年代的GC
老年代的GC一般发生在当MinorGC向老年代移动数据,老年代空间不足时;
分代GC是对GC的优化。按照生存期的长短对java对象进行分别存储,并采用相应的GC策略。
已弃用的引用计数器算法
无法解决循环引用的问题
每次对象被引用时,需要更新引用计数器,有时间开销。
实时性 :无需等到内存不够的时候,才开始回收,运行时根据对象的计数器是否为0,就可以直接回收。
应用无需挂起 :在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报outofmember 错误。
区域性 :更新对象的计数器时,只是影响到该对象,不会扫描全部对象
Comments