16 min to read
Hi space_invader
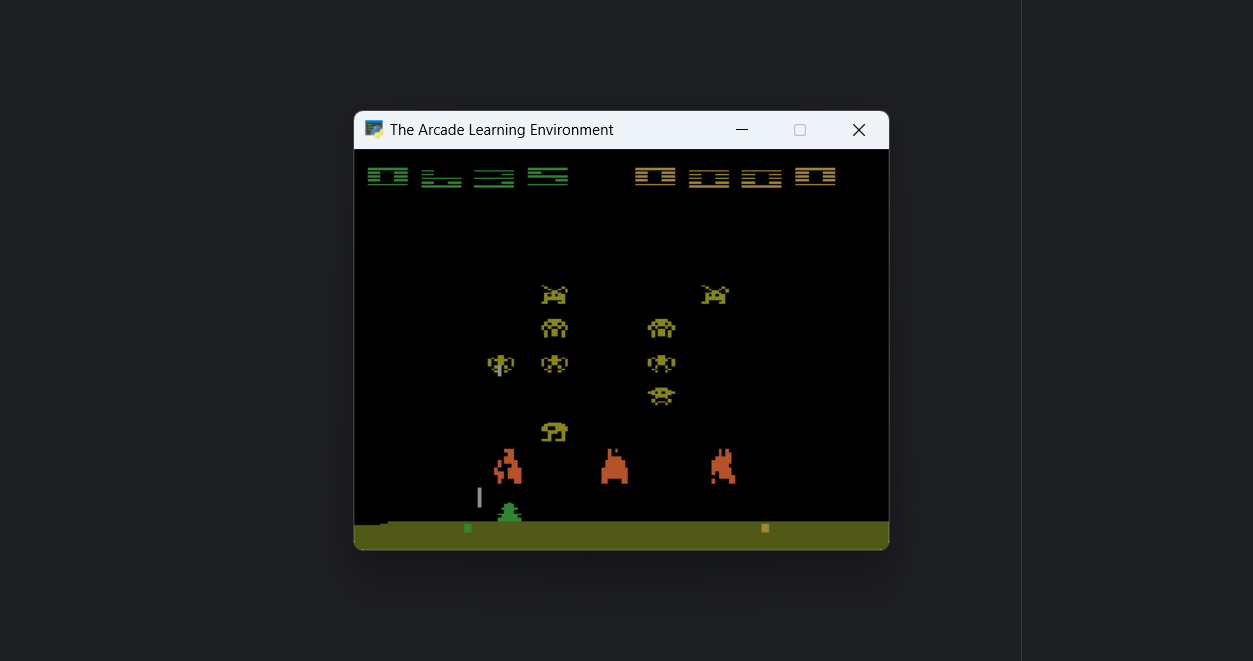
在没有调参的基础上,大概训练了5个小时左右,最终score大概在500左右;
训练过程中的score变化情况如下:
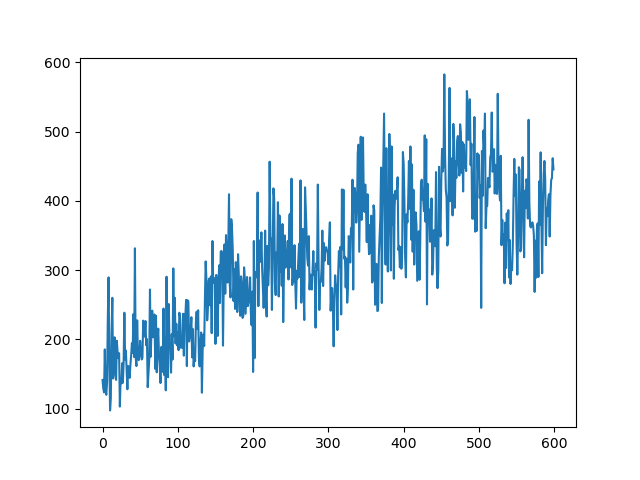 横坐标是训练轮次,纵坐标是得分;
横坐标是训练轮次,纵坐标是得分;
模型文件地址:https://github.com/luckyPT/QuickMachineLearning/tree/master/src/reinforcement_learning
像一个刚玩不久的小朋友
import gym
import time
import math
import random
import numpy as np
from torch.distributions import Categorical
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from tqdm import trange
from itertools import count
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
import random, datetime, os, copy
# Gym is an OpenAI toolkit for RL
import gym
from gym.spaces import Box
from gym.wrappers import FrameStack
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
print(device)
class SkipFrame(gym.Wrapper):
def __init__(self, env, skip):
"""Return only every `skip`-th frame"""
super().__init__(env)
self._skip = skip
def step(self, action):
"""Repeat action, and sum reward"""
total_reward = 0.0
for i in range(self._skip):
# Accumulate reward and repeat the same action
obs, reward, done, trunk, info = self.env.step(action)
total_reward += reward
if done:
break
return obs, total_reward, done, trunk, info
class GrayScaleObservation(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
obs_shape = self.observation_space.shape[:2]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def permute_orientation(self, observation):
# permute [H, W, C] array to [C, H, W] tensor
observation = np.transpose(observation, (2, 0, 1))
observation = torch.tensor(observation.copy(), dtype=torch.float)
return observation
def observation(self, observation):
observation = self.permute_orientation(observation)
transform = T.Grayscale()
observation = transform(observation)
return observation
class ResizeObservation(gym.ObservationWrapper):
def __init__(self, env, shape):
super().__init__(env)
if isinstance(shape, int):
self.shape = (shape, shape)
else:
self.shape = tuple(shape)
obs_shape = self.shape + self.observation_space.shape[2:]
self.observation_space = Box(low=0, high=255, shape=obs_shape, dtype=np.uint8)
def observation(self, observation):
transforms = T.Compose(
[T.Resize(self.shape), T.Normalize(0, 255)]
)
observation = transforms(observation).squeeze(0)
return observation
class Model(nn.Module):
def __init__(self):
super().__init__()
self.actor = nn.Sequential(
nn.Conv2d(in_channels=4, out_channels=32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(3136, 512),
nn.ReLU(),
nn.Linear(512, env.action_space.n)
) # value
self.critic = nn.Sequential(
nn.Conv2d(in_channels=4, out_channels=32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(3136, 512),
nn.ReLU(),
nn.Linear(512, 1)
) # policy
def forward(self, obs):
return Categorical(logits=self.actor(obs)), self.critic(obs).reshape(-1)
class PPOSolver:
def __init__(self):
self.rewards = []
self.gamma = 0.95
self.lamda = 0.95
self.worker_steps = 4096
self.n_mini_batch = 4
self.epochs = 30
self.save_directory = "./mario_ppo"
self.batch_size = self.worker_steps
self.mini_batch_size = self.batch_size // self.n_mini_batch
self.obs, _ = env.reset() # .__array__()
self.obs = self.obs.__array__()
self.policy = Model().to(device)
self.mse_loss = nn.MSELoss()
self.optimizer = torch.optim.Adam([
{'params': self.policy.actor.parameters(), 'lr': 0.00025},
{'params': self.policy.critic.parameters(), 'lr': 0.001}
], eps=1e-4)
self. \
policy_old = Model().to(device)
self.policy_old.load_state_dict(self.policy.state_dict())
self.all_episode_rewards = []
self.all_mean_rewards = []
self.episode = 0
def save_checkpoint(self):
filename = os.path.join(self.save_directory, 'checkpoint_{}.pth'.format(self.episode))
torch.save(self.policy_old.state_dict(), f=filename)
print('Checkpoint saved to \'{}\''.format(filename))
def load_checkpoint(self, filename):
self.policy.load_state_dict(
torch.load(os.path.join(self.save_directory, filename), map_location=torch.device('cpu')))
self.policy_old.load_state_dict(
torch.load(os.path.join(self.save_directory, filename), map_location=torch.device('cpu')))
print('Resuming training from checkpoint \'{}\'.'.format(filename))
def sample(self):
rewards = np.zeros(self.worker_steps, dtype=np.float32)
actions = np.zeros(self.worker_steps, dtype=np.int32)
done = np.zeros(self.worker_steps, dtype=bool)
obs = np.zeros((self.worker_steps, 4, 84, 84), dtype=np.float32)
log_pis = np.zeros(self.worker_steps, dtype=np.float32)
values = np.zeros(self.worker_steps, dtype=np.float32)
for t in range(self.worker_steps):
with torch.no_grad():
obs[t] = self.obs
pi, v = self.policy_old(torch.tensor(self.obs, dtype=torch.float32, device=device).unsqueeze(0))
values[t] = v.cpu().numpy()
a = pi.sample()
actions[t] = a.cpu().numpy()
log_pis[t] = pi.log_prob(a).cpu().numpy()
self.obs, rewards[t], done[t], _, info = env.step(actions[t])
self.obs = self.obs.__array__()
env.render()
self.rewards.append(rewards[t])
if done[t]:
print("Done", done[t])
self.episode += 1
self.all_episode_rewards.append(np.sum(self.rewards))
self.rewards = []
env.reset()
if self.episode % 10 == 0:
print(
'Episode: {}, average reward: {}'.format(self.episode, np.mean(self.all_episode_rewards[-10:])))
self.all_mean_rewards.append(np.mean(self.all_episode_rewards[-10:]))
plt.plot(self.all_mean_rewards)
plt.savefig("{}/mean_reward_{}.png".format(self.save_directory, self.episode))
plt.clf()
self.save_checkpoint()
returns, advantages = self.calculate_advantages(done, rewards, values)
return {
'obs': torch.tensor(obs.reshape(obs.shape[0], *obs.shape[1:]), dtype=torch.float32, device=device),
'actions': torch.tensor(actions, device=device),
'values': torch.tensor(values, device=device),
'log_pis': torch.tensor(log_pis, device=device),
'advantages': torch.tensor(advantages, device=device, dtype=torch.float32),
'returns': torch.tensor(returns, device=device, dtype=torch.float32)
}
def calculate_advantages(self, done, rewards, values):
_, last_value = self.policy_old(torch.tensor(self.obs, dtype=torch.float32, device=device).unsqueeze(0))
last_value = last_value.cpu().data.numpy()
values = np.append(values, last_value)
returns = []
gae = 0
for i in reversed(range(len(rewards))):
mask = 1.0 - done[i]
delta = rewards[i] + self.gamma * values[i + 1] * mask - values[i]
gae = delta + self.gamma * self.lamda * mask * gae
returns.insert(0, gae + values[i])
adv = np.array(returns) - values[:-1]
return returns, (adv - np.mean(adv)) / (np.std(adv) + 1e-8)
def train(self, samples, clip_range):
indexes = torch.randperm(self.batch_size)
for start in range(0, self.batch_size, self.mini_batch_size):
end = start + self.mini_batch_size
mini_batch_indexes = indexes[start: end]
mini_batch = {}
for k, v in samples.items():
mini_batch[k] = v[mini_batch_indexes]
print('start train... ...')
for _ in range(self.epochs):
loss = self.calculate_loss(clip_range=clip_range, samples=mini_batch)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
print('end train... ...')
self.policy_old.load_state_dict(self.policy.state_dict())
def calculate_loss(self, samples, clip_range):
sampled_returns = samples['returns']
sampled_advantages = samples['advantages']
pi, value = self.policy(samples['obs'])
ratio = torch.exp(pi.log_prob(samples['actions']) - samples['log_pis'])
clipped_ratio = ratio.clamp(min=1.0 - clip_range, max=1.0 + clip_range)
policy_reward = torch.min(ratio * sampled_advantages, clipped_ratio * sampled_advantages)
entropy_bonus = pi.entropy()
vf_loss = self.mse_loss(value, sampled_returns)
loss = -policy_reward + 0.5 * vf_loss - 0.01 * entropy_bonus
return loss.mean()
# 训练时,应该改成:rgb_array
env = gym.make("ALE/SpaceInvaders-v5", render_mode='human')
env = FrameStack(ResizeObservation(GrayScaleObservation(SkipFrame(env, skip=4)), shape=84), num_stack=4)
episode = 0
solver = PPOSolver()
solver.load_checkpoint("D:\\myself\\reinforcement_learning\\mario_ppo\\checkpoint_5550.pth")
#--------------------train-------------------------
# solver.episode = 10000
# while True:
# solver.train(solver.sample(), 0.2)
# env.close()
print("------------------test-----------------")
print("observation:", env.observation_space.shape)
print("action:", env.action_space.n)
print("action meanning:", env.unwrapped.get_action_meanings())
obs = env.reset()
score = 0
for i in range(1000):
obs = obs[0] if isinstance(obs, tuple) else obs
obs = obs.__array__()
pi, v = solver.policy(torch.tensor(obs, dtype=torch.float32, device=device).unsqueeze(0))
obs, reward, done, terminate, _ = env.step(pi.sample().cpu().numpy()[0])
score += reward
if done or terminate:
break
time.sleep(0.01)
print("score:", score)
env.close()
Comments