1 min to read
Hadoop

官方文档:http://hadoop.apache.org/docs/stable/index.html
常见版本及其区别
Apache hadoop 最原始版本
Cloudera的CDH版本
Hortonworks版本(HDP)
安装
Apache版本
首先记得改hosts文件:实际ip地址:主机名
各个机器之间配置SSH免密登录
CDH版本
HADOOP组件
主要由hadoop-common、hadoop-hdfs、map-reduce、yarn四部分构成
HADOOP-COMMON
hdfs和mapreduce的公共库
HADOOP-HDFS
由namenode、secondaryNamenode、datanode进程构成,其结构图如下:
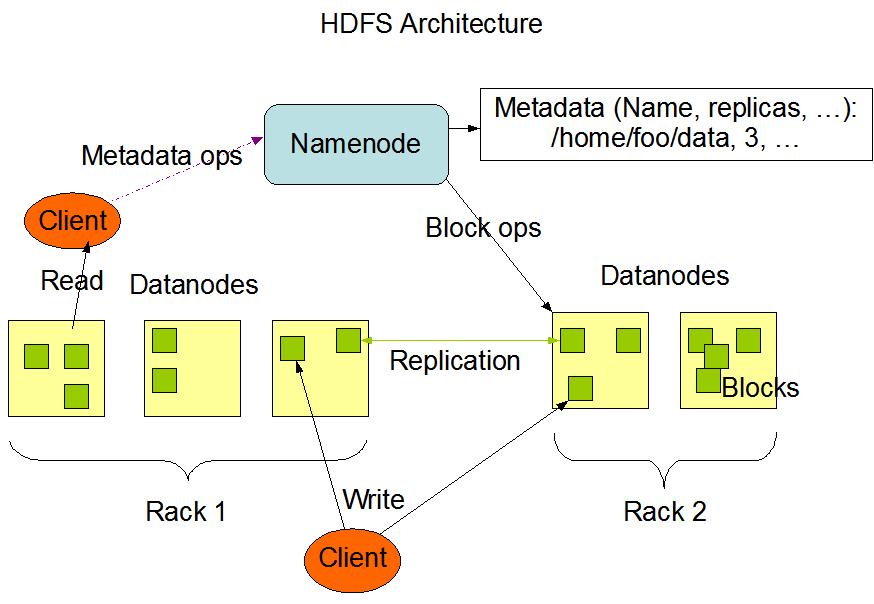
HDFS文件系统对外暴露文件的层级结构(类似于linux文件系统),然而在内部是以block序列存储的,即一个文件被分为多个block存储于多个datanode节点上。
Federation 架构:
主要为了解决HDFS的吞吐量及承载量受限于单个nameNode,并且无法根据namespace做隔离的弊端;
Federation架构通过多个独立的NameNode实现集群的横向扩展。而在存储层,各个nameNode共用统一的DataNode。Federation 架构是指由多个子集群联合构成一个 Federation 集群,通常的做法是这些子集群会共享 Datanode.然后由挂载表来维护Federation Namespace 到子集群 Namespace 间的映射关系。架构描述如下:
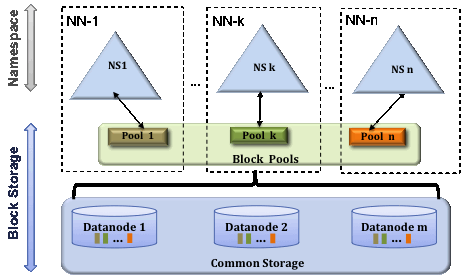
具体实现分为veiwFS-based架构以及router-based架构:
viewFS-based 的HDFS的访问,是通过挂载表完成Federation Namespace 到子集群 Namespace 间的映射关系,这个挂载表存储在客户端本地的配置文件里面。由客户端解析,从而访问正确的子集群。
这种架构的问题是:挂载表是由客户端实现,修改代码逻辑需要考虑新老客户端的兼容性并分发新的客户端,另外在实现子集群 Namespace 的 Rebalance 时,难以保证所有客户端同步更新到新的挂载表。
router-based架构相当于在client与HDFS之间增加了一个中间层;
namenode进程
HDFS类似主从(master/slave)架构,一个集群中只有一个nameNode进程,其角色类似于master;主要负责对外展示文件的层级结构、管理客户端对文件的访问,如:打开、关闭、重命名等、决定文件的block与datanode之间的映射关系。
nameNode进程相关信息都会记录在FsImage和editlog两个文件中,可以通过配置保持一份或者多份同步更新,在某个节点失败之后,只要文件存在便可以迅速恢复。
关于权限控制,与linux系统有很大相似之处,可以通过chown命令修改相关文件夹、文件的权限。FS客户端一般取客户端进程所在主机名作为用户名。超级用户是运行nameNode进程的用户。参考:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_permissions_guide.html#Shell%E5%91%BD%E4%BB%A4%E5%8F%98%E6%9B%B4
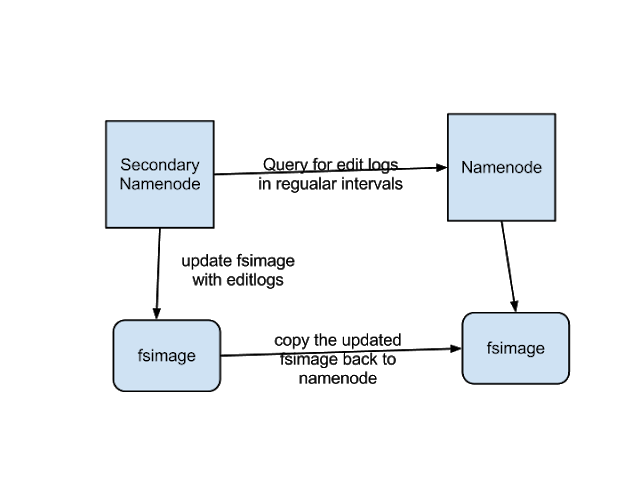
secondaryNamenode
nameNode运行时间太长,会导致editlog太大,文件间的管理就会变的复杂,难度也会有所增大;主要负责协助nameNode管理editLog,比如将editLog合并到fsImage;
具体逻辑如下图:
datanode
一个集群中有多个dataNode,通常每台机器部署1个。主要负责数据存储、处理来自客户端的读写请求等(包括block的创建删除)。
DataNode节点的启动很简单,拷贝NameNode节点配置,在danaNode节点执行:./sbin/hadoop-daemon.sh start datanode
副本的存储配置时hdfs系统的优化重点,直接关系到集群的可靠性和性能(如一个文件的两个副本与文件存储在同一个机器上,则很难起到备份作用);受硬件布局、带宽等很多因素影响。
MAP-REDUCE
Mapper
将key/value集合映射为key/value集合,映射前后的数据类型和数据量可以不一致(可以完成一对多的映射)
map->group->sorted-partitioned 最终partition之后的数量一般于reducer需要执行的task的数量相等(注意不是和reduceer数量相等)
Reucer
将key相同的value构成的集合转成更小的一个value集合,可以自行设置reducer的数量,一般为计算node的0.95或1.75倍
shuffle(译为拉取)&group&sort:采用fetch方式取mapper的输出并做聚合(因为相同的key可能在不同的mapper输出里面),这两个过程是同时进行的。
secondary sort:如果设定了自定义的排序与前面的sort不同,会执行这一过程
Reduce:输入key以及对应的value的集合;输出一般是写出到文件系统
YARN
YARN是集群资源管理的组件,主要有resourceManager和nodeManager进程构成。前者负责各个Application的资源分配,后者负责各自节点的CPU、内存、硬盘、网络等的监控,并负责报告给resourceManager进程。结构图如下:
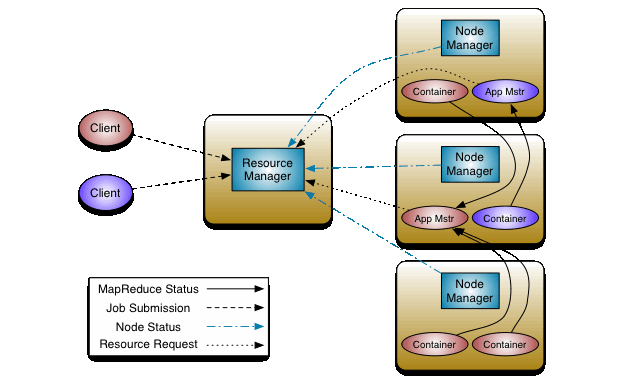
resourceManager由两部分构成,scheduler和applicationManager
scheduler仅负责资源分配,支持不同的调度策略如:CapacityScheduler,FairScheduler。并不处理application的相关消息,也不关注application的状态等。
application向applicationManager提交任务,由applicationManager向scheduler申请资源,之后负责启动容器,选取applicationMaster,并且提供一些容错机制,如applicationMaser失败之后重试等
Nodemanager启动
yarn-site.xml配置:yarn.resourcemanager.resource-tracker.address,确保nodemanager可以找到resourcemanager;执行:./sbin/yarn-daemon.sh start nodemanager
认证机制
kerberos认证机制
通过Principal(类似于用户名)+keytab文件(类似于秘钥)
配置方式一,启动java程序是增加如下属性配置:
-Dhadoop.property.hadoop.security.authentication=kerberos
-Dhadoop.property.hadoop.client.keytab.file=/home/panteng.keytab
-Dhadoop.property.hadoop.client.kerberos.principal=panteng@XXX.HADOOP
配置方式二,在core-site.xml中增加如下配置:
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hadoop.client.kerberos.principal</name>
<value>panteng@XXX.HADOOP</value>
</property>
<property>
<name>hadoop.client.keytab.file</name>
<value>path/panteng.keytab</value>
</property>
高可用
常见的故障一般为namenode节点挂掉、数据节点挂掉、网络故障等(网络隔离,不通)。
高可用参考资料:https://blog.csdn.net/liu123641191/article/details/80737761
其他
通过Reservation System实现资源预订机制,可确保重要任务有足够可用资源。
通过YARN Federation 实现资源扩容与缩放
常见问题
- 如何使用map reduce实现join操作
map阶段输出key/value,其中key是join的字段,value需要根据输入文件名称,进行区分(比如加前缀,表明是哪个表/文件的数据);
reduce阶段,输入是key以及两个表中这个key对应的数据,然后根据前缀处理为key v1 v2的形式

Comments