2 min to read
自动驾驶预测模块实践总结
自动驾驶预测模块实践总结
1. 概述
1.1 预测模块存在的价值和必要性
预测模块不是为了存在而存在,早期的一些辅助驾驶功能,如:跟车自适应巡航,没有预测模块也是可以达到效果预期的。

随着对辅助驾驶功能要求逐步提高,需要在更复杂的工况下,完成安全、舒适、高效的控车,对周边交通参与者的意图以及未来轨迹有更准确的了解与把握成为必要条件之一,预测模块主要功能就是对周边交通参与者的意图&轨迹进行预测;
 |
 |
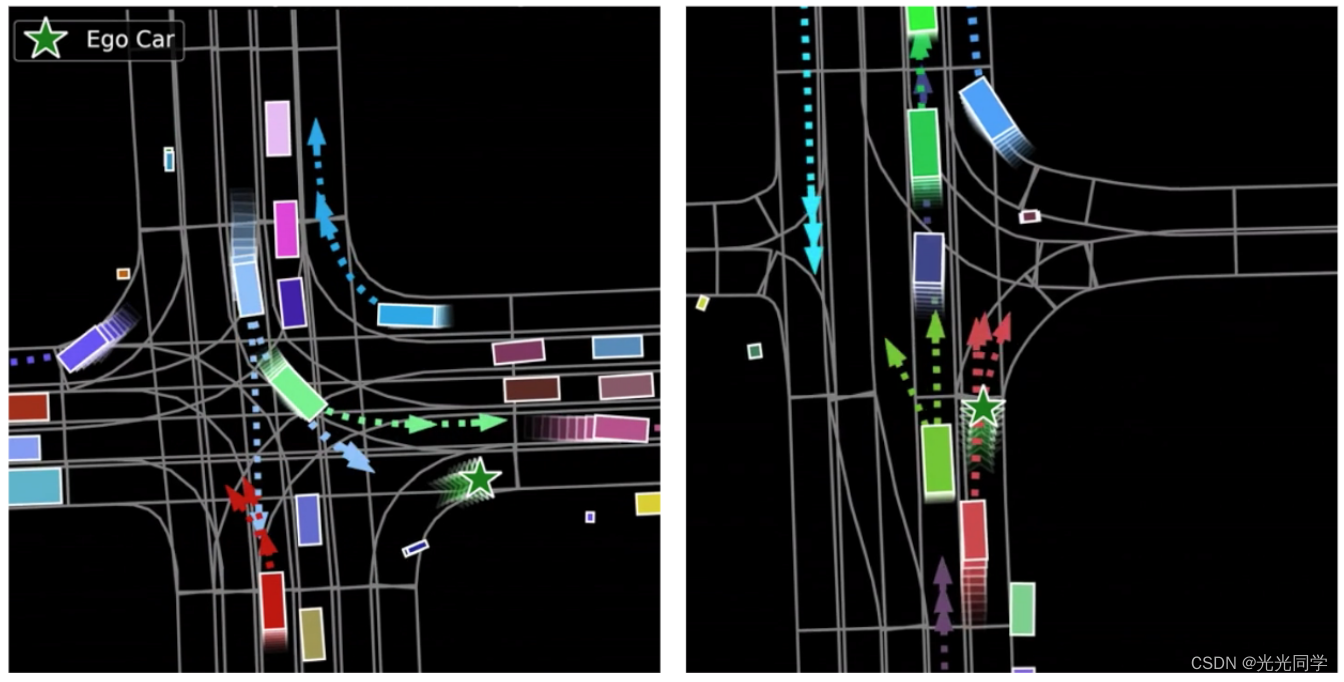
case1:早期ACC策略,主要关注前车速度和跟车距离,当面临前车因为前方路况突然切出时,自车很可能响应不及时;如果能提前预测出前车切出,则可以更早的将关注点放到前车前方,争取更多的时间;
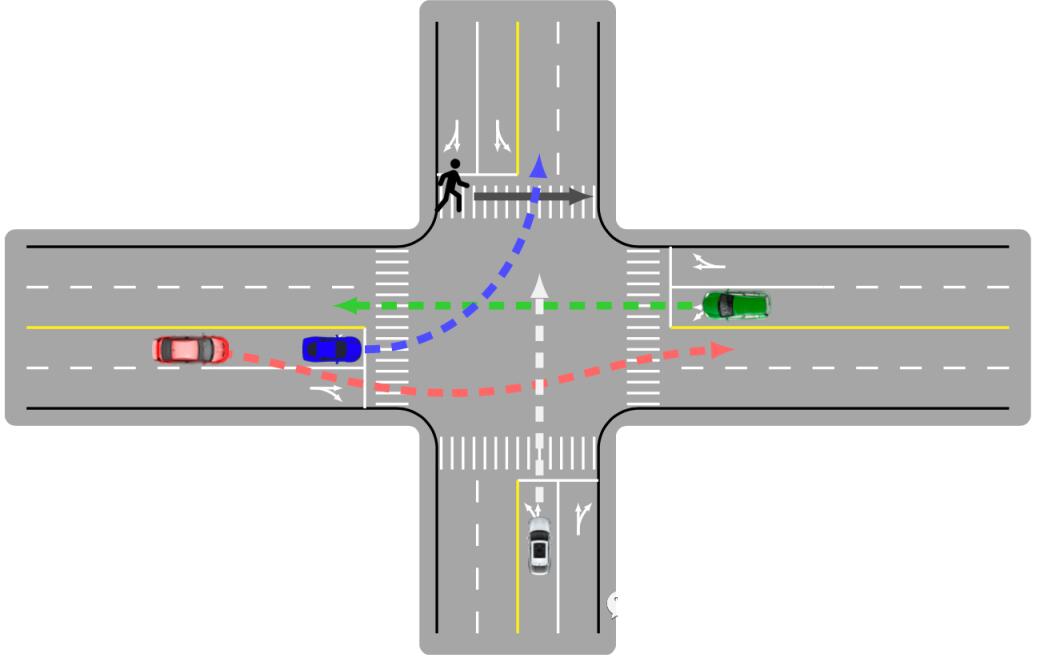
case2:泊车业务第一版,针对行人策略时划定一个危险区域,只要区域内有行人,就刹停;
进阶版:可以准确识别动静,如果静态障碍物则选择是否绕障碍,如果时动态障碍物,则刹停;
再次进阶:针对动态障碍物,区分沿途和横穿,针对横穿目标刹停,针对沿途目标进行绕障或者直行;
再次进阶:针对横穿目标,结合轨迹进行强让决策;
预测模块在自动驾驶中的定位
核心点在于:自动驾驶是一项系统工程,目标是实现安全、舒适、高效的控车
预测模块是系统工程的一环,预测的目标是配合决策规划模块完成系统工程的目标;

常见误区:
- 过分追求和强调模块级目标(如:ADE、FDE),忽略系统效果;
- 把系统效果问题局限于预测模块内部解决,忽略上下游的配合;
如:切入误判的情况下,可以配合caution机制协作完成舒适控车; - 模块之间不考虑包容性;(包容 ≠ 和稀泥,模块间还是要有明确的职责划分)
最佳实践
正向迭代的保障工具链
基本逻辑是实现仿真 → 可视化 → 效果评测功能;
整套工具链从【能用】 → 【易用、好用、高效】 → 【真正的赋能方案迭代,保证效果】;
功能层面的仿真、可视化、评测只是冰山表面上的东西,更深层次有以下几个关键因素: ① 数据分布、数据有效性(去除上游问题数据、陈旧的数据,比如:参考线信息的增加)、数据标注质量;
① 数据分布、数据有效性(去除上游问题数据、陈旧的数据,比如:参考线信息的增加)、数据标注质量;
② 评测指标的合理性、完备性;(横向FDE,跳变次数,最早触发时刻、轨迹异常等)
③ 持续关注、提升易用性和效率的意识;比如:快速精准定位时间戳、目标筛选、自定义对比颜色、轨迹时长、真值显示、覆盖式显隐等
价值点:
- 验证策略的有效性,支持策略的选择和迭代;
- 在复杂的策略体系下,研发者很难对所有策略细节都能了然于心,某一个策略改动往往影响到其他策略,超出研发者的预期;实践中发现了大量的预期之外的影响;
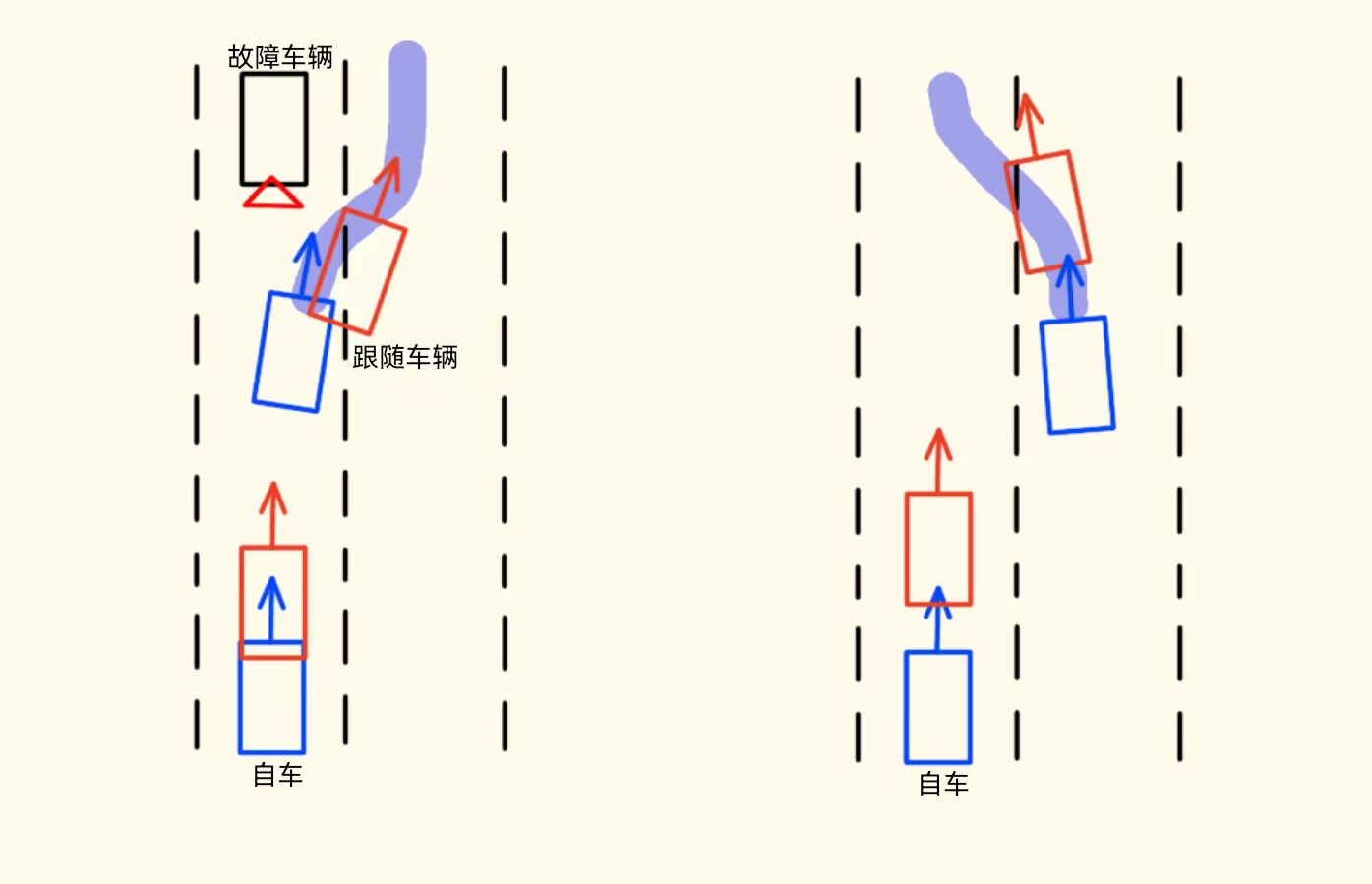
示例:目标加速度系数的调整,解决跟车刹不停问题 0.5 → 1.0
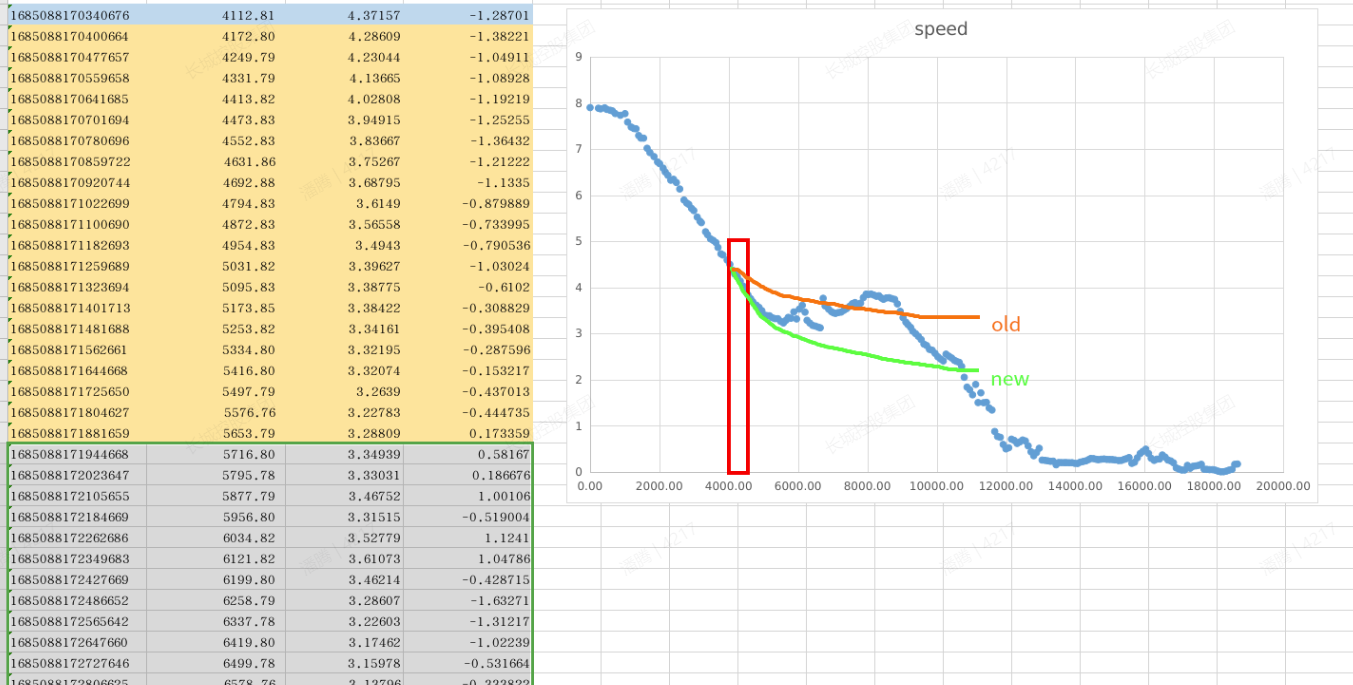
 解决方案优化:减速场景下,系数0.5 → 1.0,加速场景下,保持0.5不变;
解决方案优化:减速场景下,系数0.5 → 1.0,加速场景下,保持0.5不变;
轨迹跳变:为了防止轨迹跳变,在加速度在0附近时,对系数加了平滑策略;
由rule base到learning base的转型
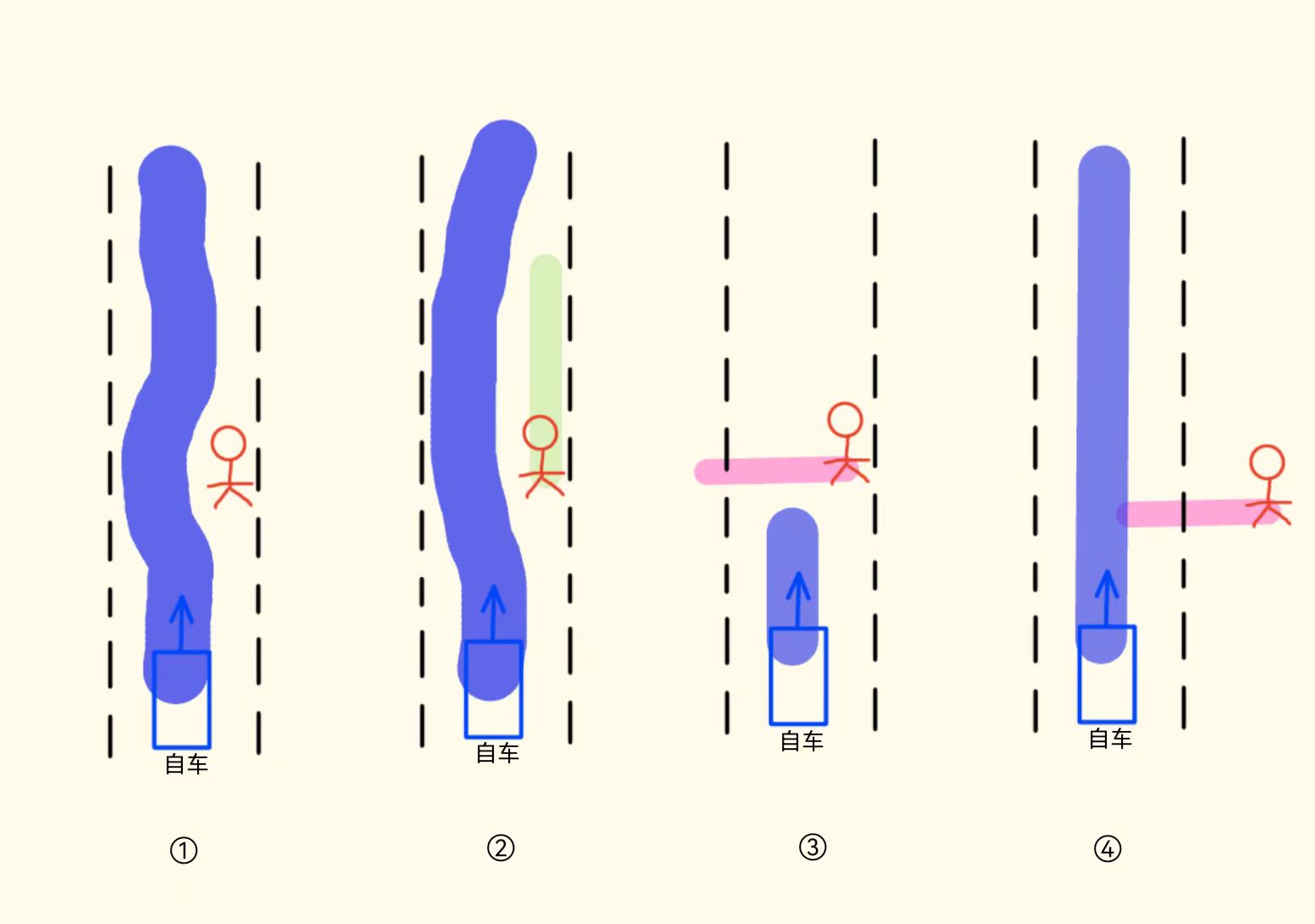
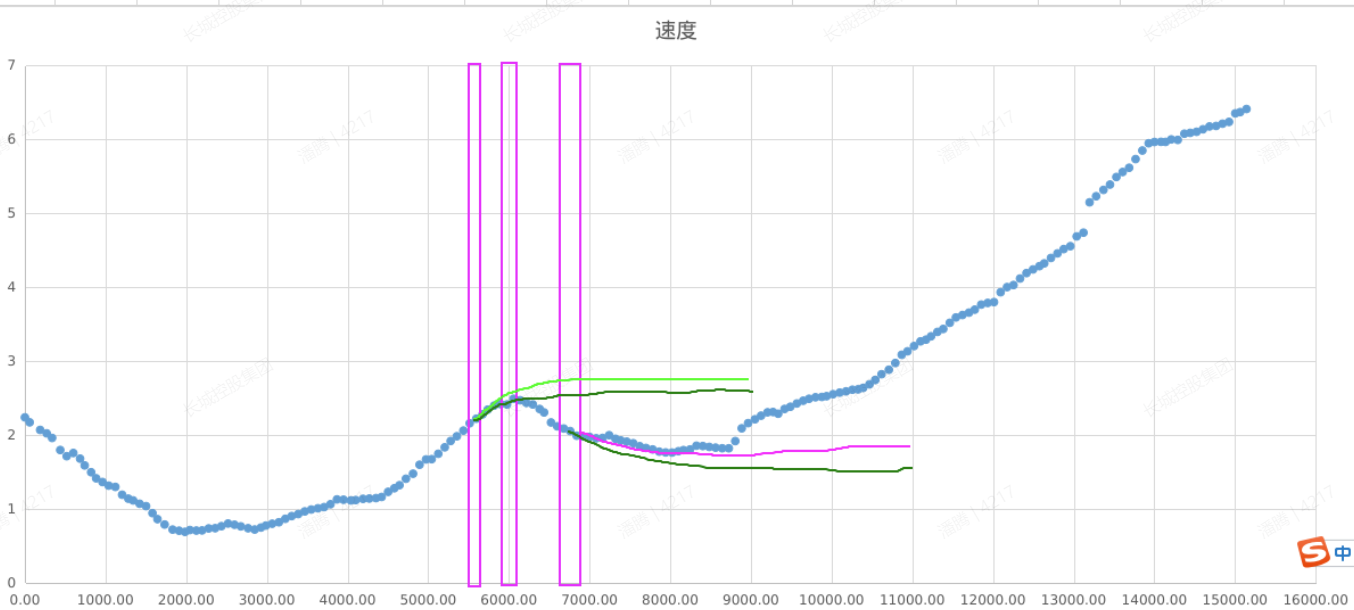
迭代案例(Demo):部分斜穿行为被识别为同向行驶,不刹车或者刹车晚;
step1:寻找对应决策逻辑
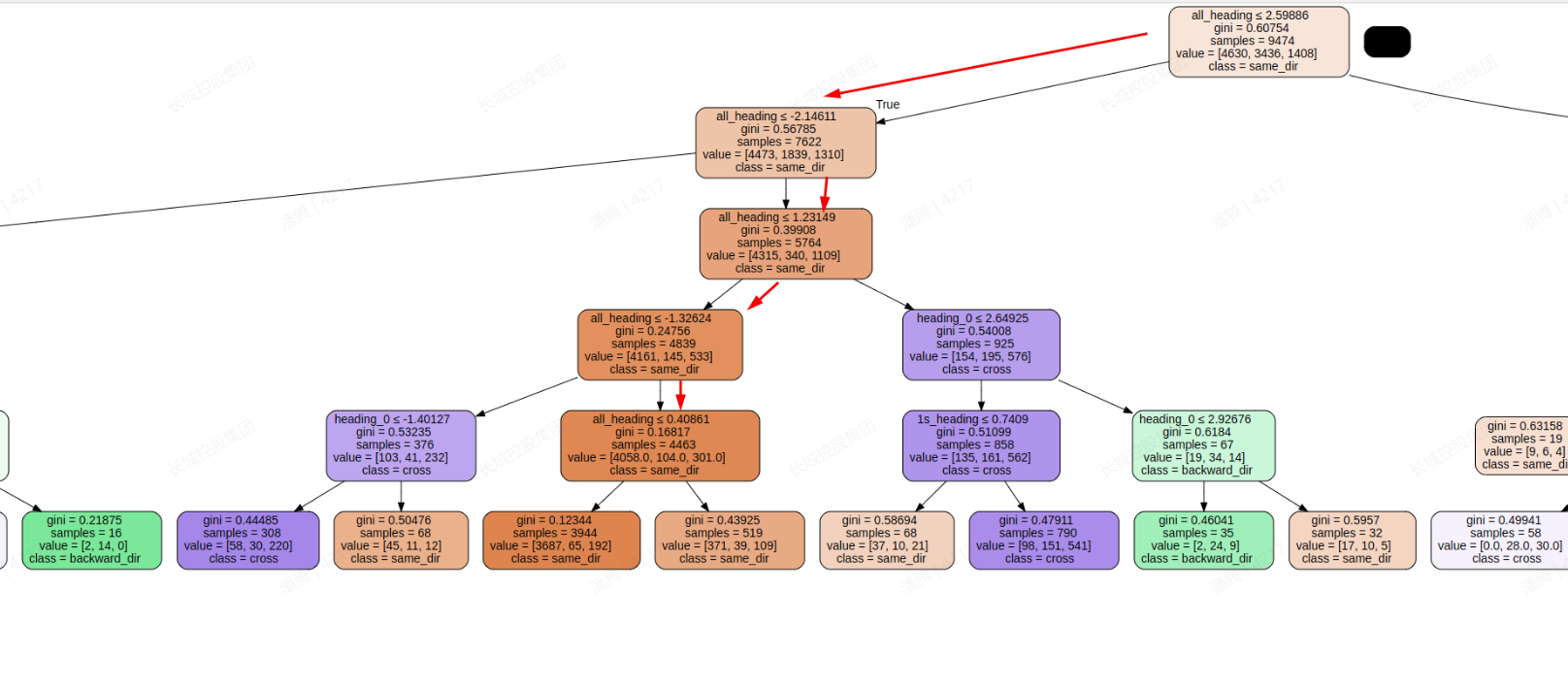 代码层面的语义如下:
代码层面的语义如下:
if(all_headding > -1.3 && all_headding < 1.23){
识别为同向
}
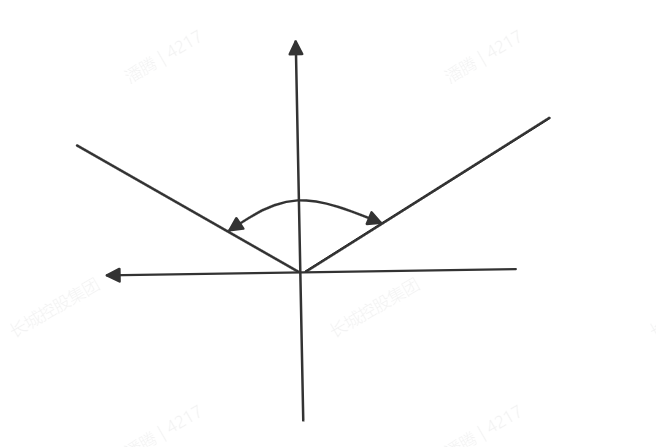
step2:寻找对应空间下,同向标签的样本数值分布情况
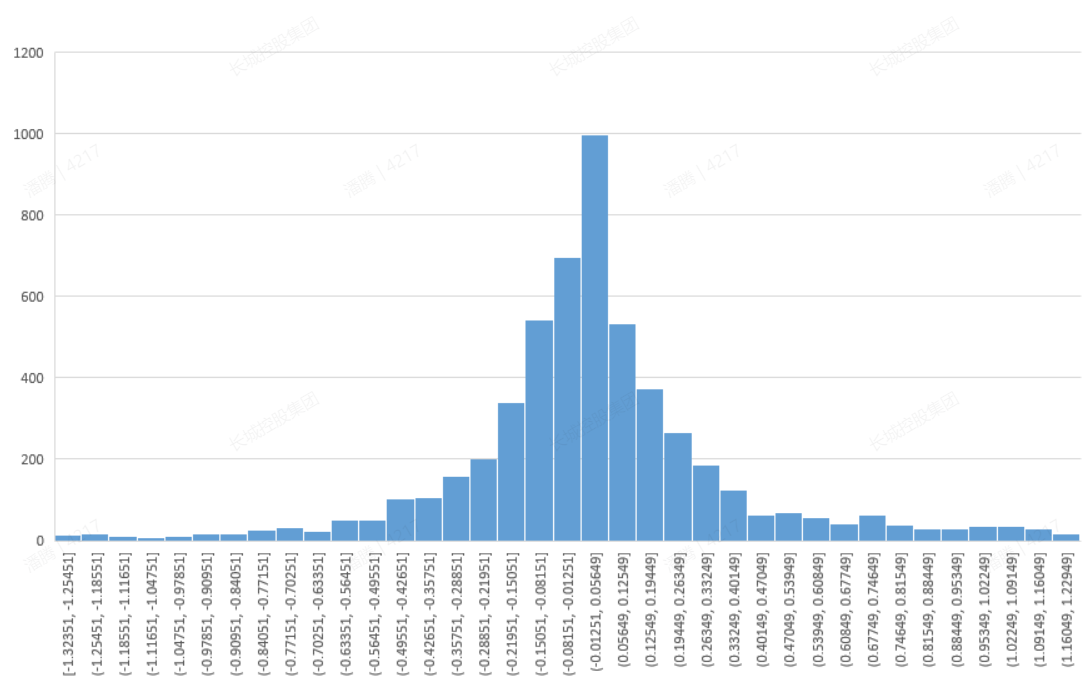
step3.1:快速解决方案
结合样本分布情况以及人工经验,对决策树进行后剪枝处理;具体逻辑是:
根据先验知识,走到某个节点时,切换为人工规则;
step3.2:长期优化
寻找数据分布中的边缘值对应的case
基本都是标注错误,目标先“横穿”,后转弯为同向;但是标注的时候起止时间没有控制好;
调整训练数据,重新训练模型;
PS:2022年,特斯拉AI day的分享上,也提到了决策树的方案;
具体细节没有详细展开,但无非就是分裂方式基于if else,还是先做线性加权,然后再用if else选择左右;
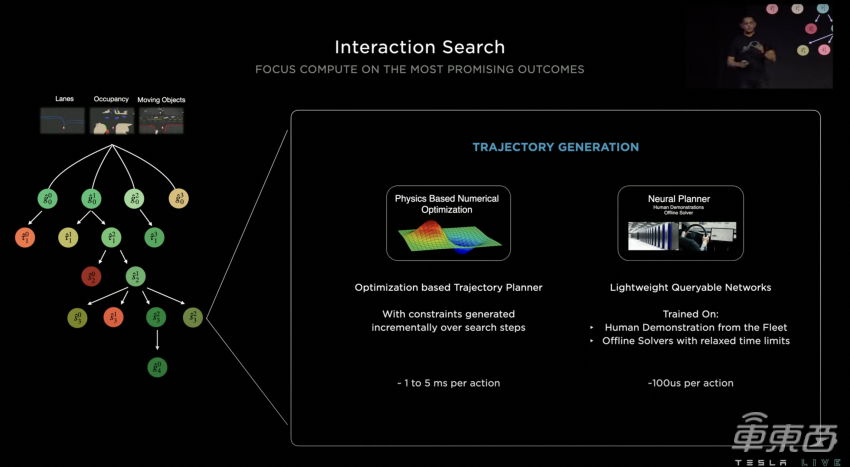
实际上决策树是在追求可解释性与算法效果之间平衡的绝佳算法,2018年之前,kaggle竞赛中很多最优方案就是基于决策树的;(gbdt、xgboost、light gbm等),2018年之后,即使在神经网络逐渐流行的情况下,仍然有很多决策树相关的算法在被广泛使用,典型的如:Facebook的GBDT + LR推荐机制;
rule base开发的本质
① 不断的寻找、发现新的划分维度
② 寻找不同维度的最佳切分点
③ 寻找维度之间的有效组合方式
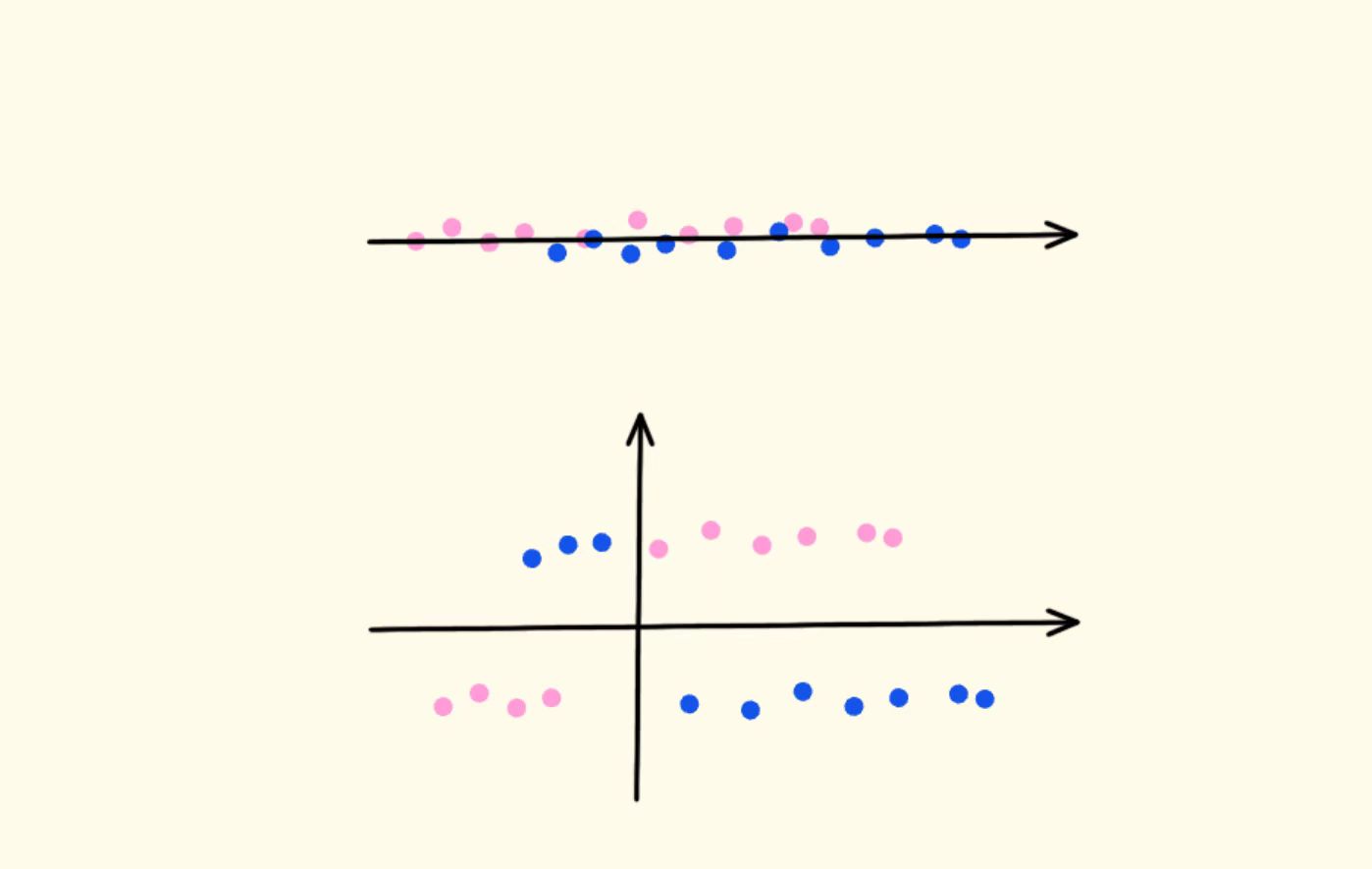 扩展维度的一些思路:
扩展维度的一些思路:
|
某一维度 + 时间维度,扩展出变化趋势或者平均值的维度 (加速度、yaw rate等;很多问题,根据某一时刻下的空间位置信息很难分析解决,但如果根据连续的一段时间的空间位置数据,就能得到更多有效信息); |
|
相同维度,不同实体之间的差值对比; (比如:目标走向和车道线走向的夹角;某一动态目标和静态目标的相对位置关系;时距差值) |
|
不同维度之间的计算关系: 距离 / 速度 = 时距; f(距离,当前速度,碰撞点) = 减速度 |
| 同一个维度指标,不同来源的校验;(障碍物box朝向、障碍物速度方向、位移方向、不同传感器的值) |
对rule base & learning base & deep learning的看法
从算法效果的能力上限来讲,一定是:deep learning > learning > rule
而且随着数据、算力的增加,learning的占比权重会逐步提高;
实际落地,还要考虑很多因素,如:
- 算法对数据和算力的依赖
- 算法的研发周期
- 针对badcase的修复难度
- 结果的可解释性
三种解决方案并不是互斥的,反而应该是相互配合,取长补短;
就目前对learning & deep learning的应用来看,实际落地过程中,几乎都是算法 + 规则的方式实现,比如:
目前量产的自动驾驶系统,感知模块以深度学习为主,但仍然有后处理模块和融合模块来解决一些明显的误检、漏检问题;
做好预测的关键要素
数据驱动策略
- 逻辑经过了多少数据的评估
- 这些数据与生产环境的数据情况是否一致
- 数据中是否包含“负样本”数据,是否能支撑评估负面收益
效率工具
⽀撑批量数据处理、分析、可视化的⼯具/平台;
⽀撑具体问题的Bug分析、根因定位的⼯具(日志体系、可视化工具)
⽀撑⼯程⼦逻辑调⽤频率,效果评估的工具;
流程
技术方案评审
code review
仿真评测
deeplearning的方法综述
以2020年为分割线,2020之前主要以图像领域的深度学习技术进行轨迹预测,对Image进行栅格化,基于CNN算子进行编码 - 解码;
2020年,vector net论文提出向量方式对输入进行编码,这种方式逐步成为主流,并且逐步应用attention机制进行编码和解码;
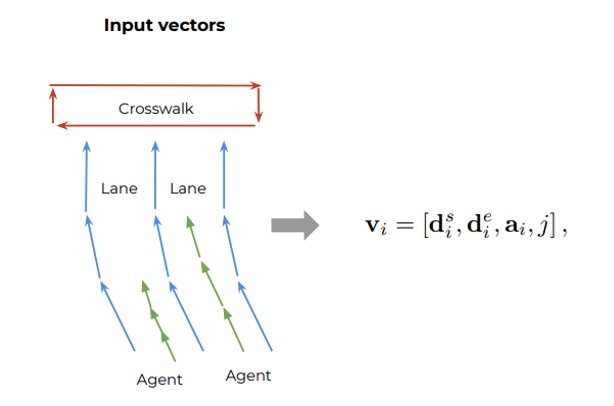
架构方面,基本采用encoder-decoder架构;
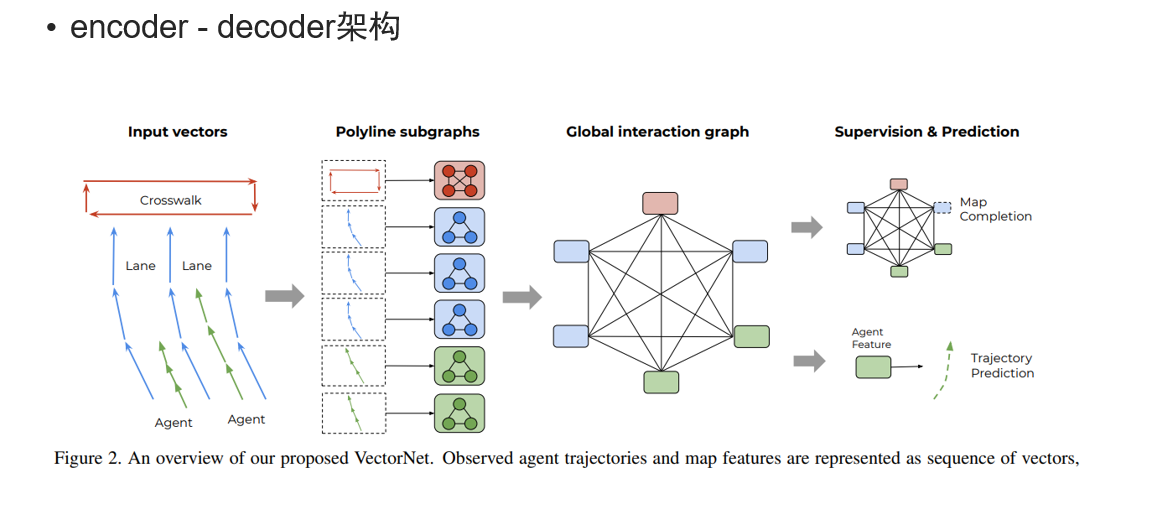
关于transfmer和attention机制的应用
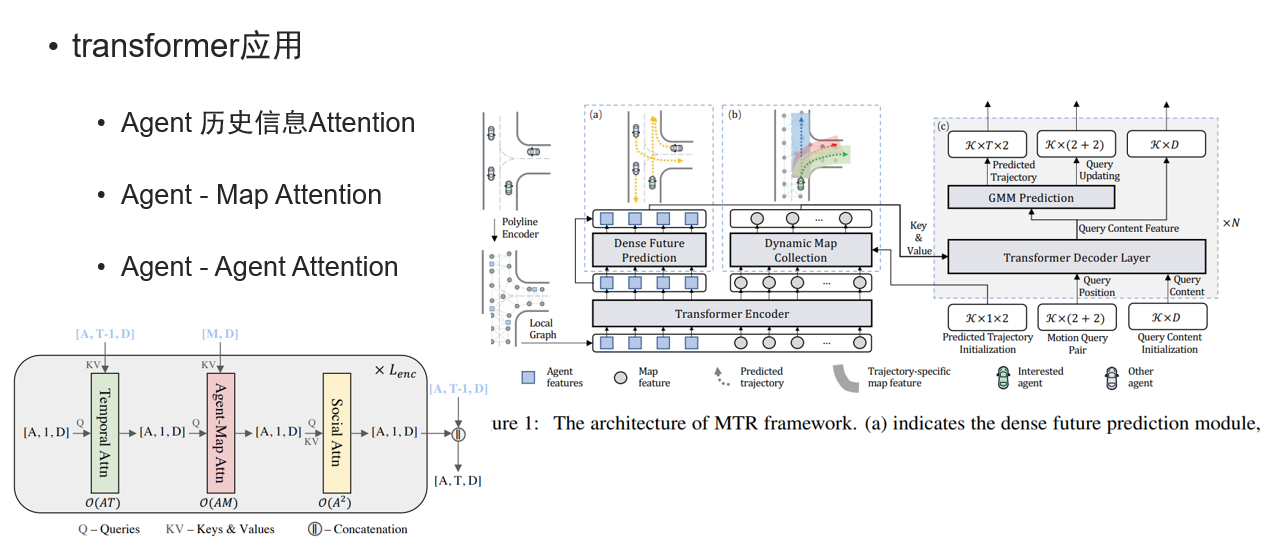
一些典型的预测范式
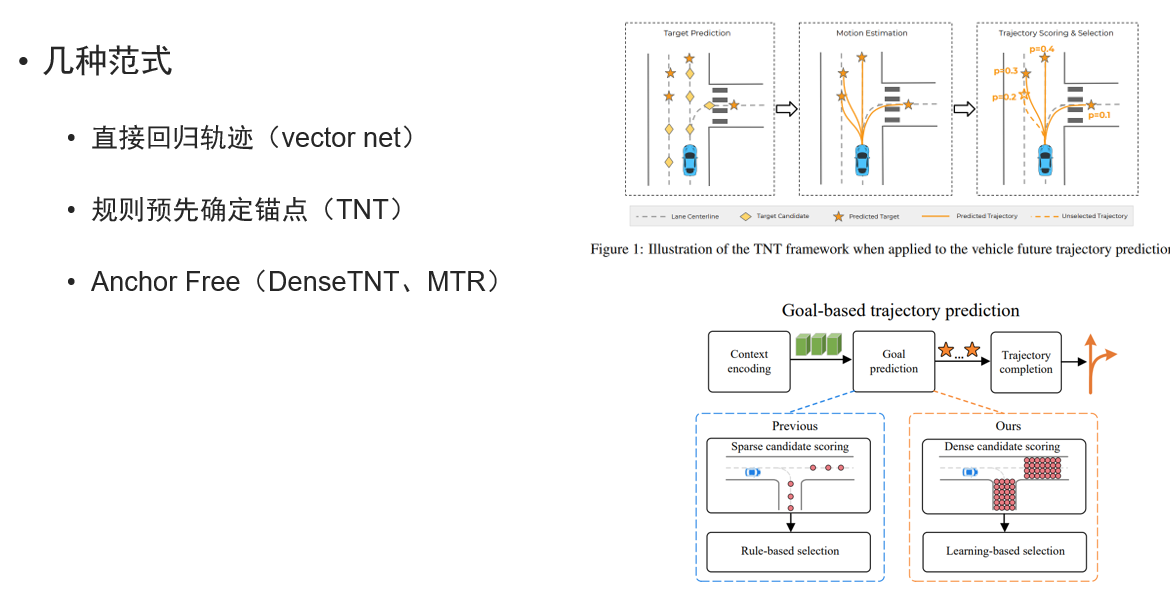
关于数据复用降低计算复杂度的一些算法,目前也有一些主机厂逐步探索落地
如:HIVT、QC-NET、QC-next
Comments