1 min to read
大模型综述
大模型综述

定义
目前针对大模型尚未找到一个公认的定义
从表象上看,通常参数量超过十亿,甚至超越百亿、千亿级别;参数量纲可用B来衡量,1B是10亿个参数;
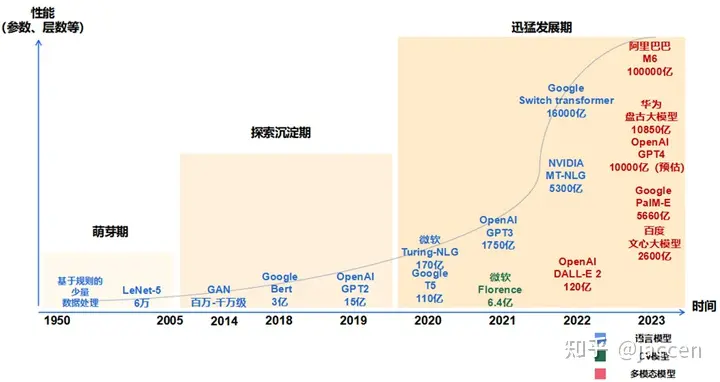
除了参数之外,更重要的是背后涌现出的模型能力(专业说法是:涌现能力),这是区别于小模型核心
所谓涌现能力,指的是一个复杂系统拥有很多微小的个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观体现出的个体无法解释的现象,比如:大模型展现出的逻辑推理能力,泛化能力,迁移学习、领域融合、上下文关联逐步推理能力(思维链)等
大模型分类
从输入类型,可分为
- 语言大模型:如gpt系列(openAI)、Bard(Google)、文心一言(百度)
- 视觉大模型:如Google的VIT系列
- 多模态大模型:处理多种类型的呼叫
按照应用领域分类
- 通用大模型
- 行业大模型
大语言模型如何产生的
大语言模型依然属于机器学习的范畴,支撑大模型诞生的关键因素仍然是:数据、算法、算力、任务定义这四个方面;
数据
大模型常用语料如下:
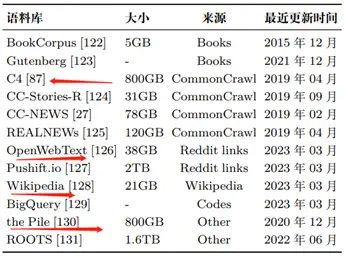 GPT-3(175B)是在混合数据集(共 3000 亿 token) 上进行训练的,包括 CommonCrawl 、WebText2、 Books1、Books2 和 Wikipedia。
GPT-3(175B)是在混合数据集(共 3000 亿 token) 上进行训练的,包括 CommonCrawl 、WebText2、 Books1、Books2 和 Wikipedia。
PaLM(540B)使用了一个由社交媒体对话、过滤 后的网页、书籍、Github、多语言维基百科和新闻组成的预训 练数据集,共包含 7800 亿 token。
LLaMA 从多个数据源中提取训练数据,包括 CommonCrawl、C4 、Github、Wikipedia、书籍、ArXiv 和 StackExchange。
LLaMA(6B)和 LLaMA(13B)的训练数 据大小为 1.0 万亿 token,而 LLaMA(32B)和 LLaMA(65B) 使用了 1.4 万亿 token。
通常来讲,更多的数据有利于模型效果的提升,甚至通过扩增数据可以压缩模型大小
比如:Chinchilla参数量70B(具有更多的训练 token)通过在相同的计算预算下增加数据规模,优于其对应的模型 Gopher(280B)(具有更大的模型规模)。
算法
以Transformer算法为核心进行微调,比如:
-
layer normalize层前置, 让训练效果更佳稳定
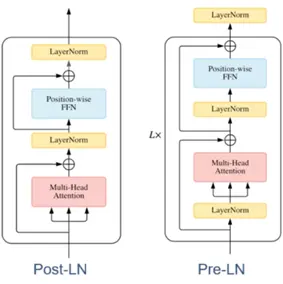
- 激活函数选择GLU、GeLU、SwiGLU、GeGLU
- 学习位置编码而非固定的编码
- 引入相对位置编码,通过键和查询之间偏移量来生成位置编码
- 稀疏注意力机制优化资源消耗
算力
多卡同时训练,并利用一些可扩展的并行训练技术来提升速度,如:数据并行、流水线并行、张量并行等
混合精度训练提升训练速度
任务定义
大模型的诞生通常显示无监督任务下的预训练,然后是特定监督任务下的微调;
大模型中常用的两种微调策略:
指令微调
指令微调目的是为了解锁预训练模型一些潜在的能力;
对齐微调(反馈强化学习)
与人类的价值观、偏好对齐;
参考资料
https://zhuanlan.zhihu.com/p/662673023
https://zhuanlan.zhihu.com/p/621438653
Comments