1 min to read
大模型与自动驾驶结合范式
利用大型语言模型的推理能力赋能自动驾驶的技术方案
相关论文
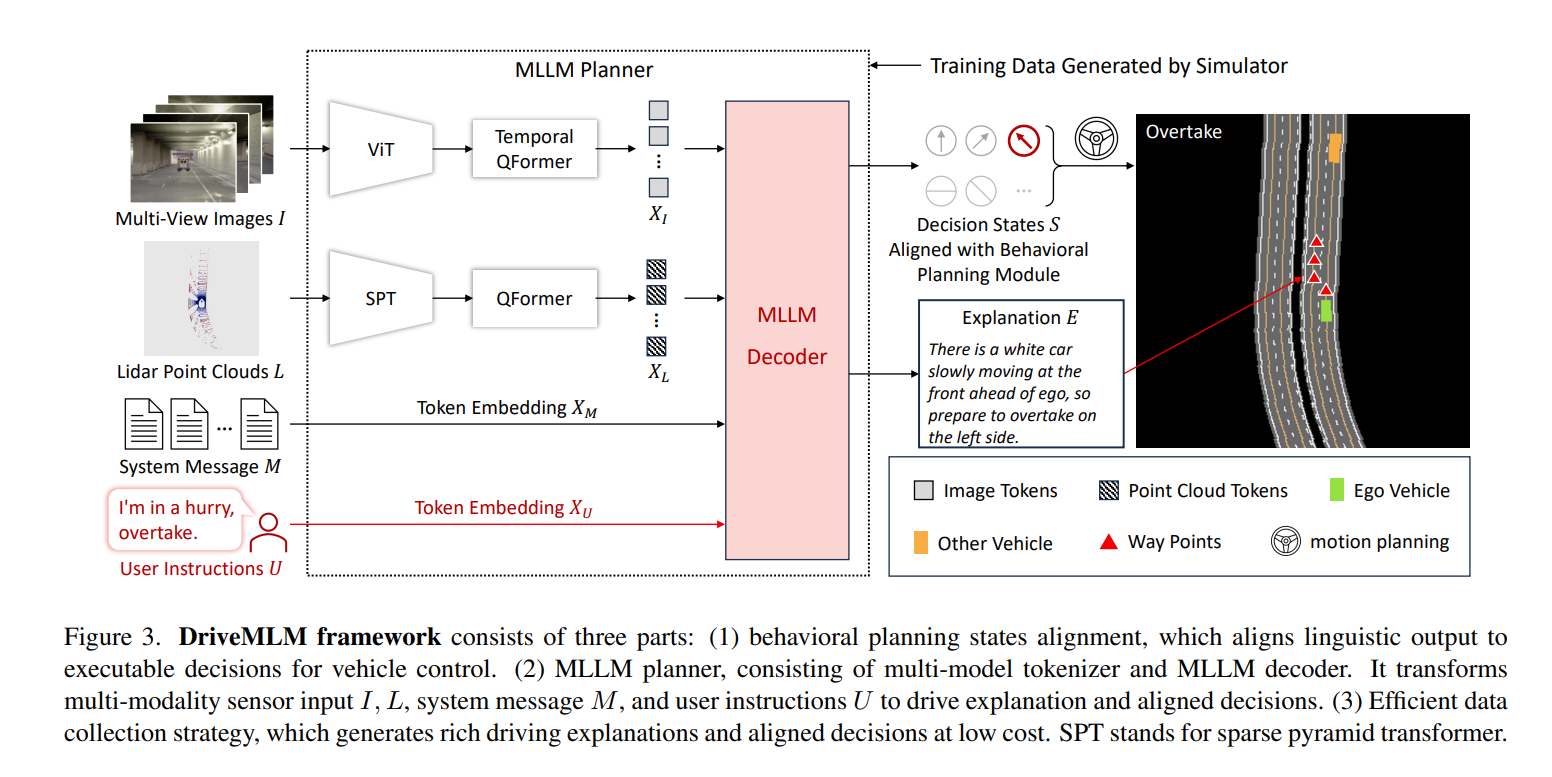
整体架构遵循编码器和解码器的逻辑架构,“编码器”实际上是由多个编码器构成,用于处理不同的模态的输入;
输入包含:
- 摄像头数据
- 激光雷达点云
- 语言数据
- 预定义的交通规则
- 驾驶习惯的描述
- 用户语音指令
这些输入经过各自编码器转码成向量,输入到解码器中;
解码器的输出是决策状态及对决策的解释;
决策状态包含速度决策和路径决策:
速度决策包含:匀速、加速、减速、刹停;
路径决策包含:跟随、左换道、右换道等;
LMDrive: Closed-Loop End-to-End Driving with Large Language Models
这里的输入增加了导航描述,输出直接是规划的轨迹点以及中间的一些辅助信息,如:预测某些指令动作是否完成、
基于视觉语言模型(VLM)开发的自动驾驶系统,核心概念是图视觉问答(GVQA);相比于VQA,纯视觉问答,GVQA中的QA与QA之间,具有一定的逻辑依赖关系,这种逻辑依赖关系可以是类似感知、预测、规划任务的关系,针对每一个任务设计问答,更符合人的逻辑思维;
实际操作中,QA被划分为了以下类别:
- 感知:在当前场景中,识别、描述、定位关键物体;
- 预测:根据感知结果,估计关键物体可能的行动
- 规划:自动驾驶车辆的所有可能的行驶方式
- 决策:对驾驶行为进行决策
- 运动:自动驾驶未来的轨迹航点
模型结构以BILP-2为基础的VLM,也可以选择其他的VLM;

Comments